基于深度学习的自然语言处理:PaddleNLP作业
https://exmachinelearning.github.io/PaddleNLP_Homework/
千言数据集:信息抽取之——DuEE注释版本
注意:本项目fork了项目『2021语言与智能技术竞赛』- 事件抽取任务基线系统,不过在此基础上增加了阅读代码时的注释,与原项目相比,需要更新到PaddlePaddle2.1.0版本,否则tensor索引没法使用Tensor,这样会使得CRF层出错!
信息抽取旨在从非结构化自然语言文本中提取结构化知识,如实体、关系、事件等。事件抽取的目标是对于给定的自然语言句子,根据预先指定的事件类型和论元角色,识别句子中所有目标事件类型的事件,并根据相应的论元角色集合抽取事件所对应的论元。其中目标事件类型 (event_type) 和论元角色 (role) 限定了抽取的范围,例如 (event_type:胜负,role:时间,胜者,败者,赛事名称)、(event_type:夺冠,role:夺冠事件,夺冠赛事,冠军)。
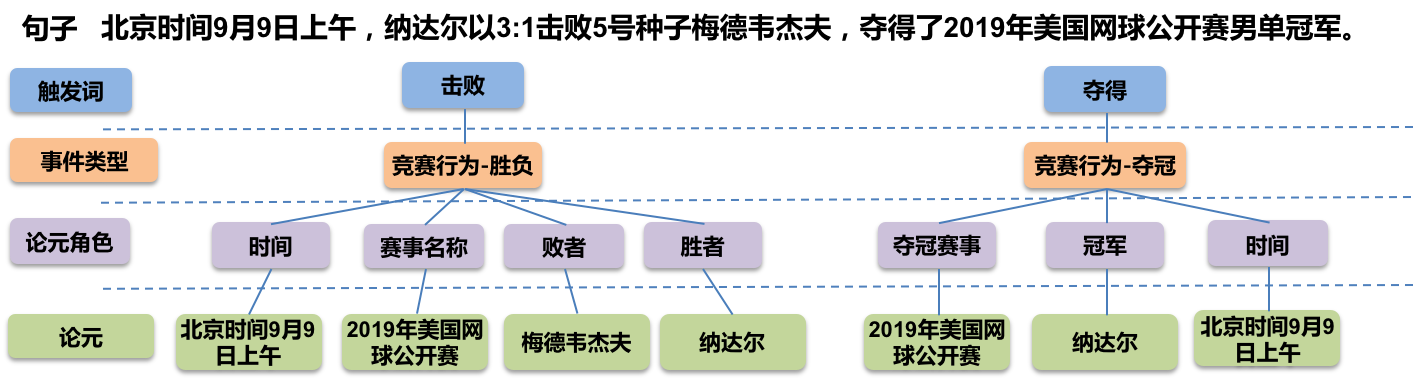
该示例展示了如何使用PaddleNLP快速复现千言数据集:信息抽取基线并进阶优化基线。
# 安装paddlenlp最新版本
!pip install --upgrade paddlenlp -i https://pypi.org/simple
%cd ~/event_extraction/
Collecting paddlenlp
[?25l Downloading https://files.pythonhosted.org/packages/63/7a/e6098c8794d7753470071f58b07843824c40ddbabe213eae458d321d2dbe/paddlenlp-2.0.3-py3-none-any.whl (451kB)
[K |████████████████████████████████| 460kB 24kB/s eta 0:00:01
[?25hRequirement already satisfied, skipping upgrade: jieba in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp) (0.42.1)
Requirement already satisfied, skipping upgrade: colorlog in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp) (4.1.0)
Requirement already satisfied, skipping upgrade: colorama in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp) (0.4.4)
Requirement already satisfied, skipping upgrade: seqeval in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp) (1.2.2)
Requirement already satisfied, skipping upgrade: h5py in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp) (2.9.0)
Requirement already satisfied, skipping upgrade: multiprocess in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp) (0.70.11.1)
Requirement already satisfied, skipping upgrade: visualdl in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp) (2.1.1)
Requirement already satisfied, skipping upgrade: scikit-learn>=0.21.3 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from seqeval->paddlenlp) (0.24.2)
Requirement already satisfied, skipping upgrade: numpy>=1.14.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from seqeval->paddlenlp) (1.20.3)
Requirement already satisfied, skipping upgrade: six in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from h5py->paddlenlp) (1.15.0)
Requirement already satisfied, skipping upgrade: dill>=0.3.3 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from multiprocess->paddlenlp) (0.3.3)
Requirement already satisfied, skipping upgrade: Flask-Babel>=1.0.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl->paddlenlp) (1.0.0)
Requirement already satisfied, skipping upgrade: pre-commit in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl->paddlenlp) (1.21.0)
Requirement already satisfied, skipping upgrade: requests in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl->paddlenlp) (2.22.0)
Requirement already satisfied, skipping upgrade: flake8>=3.7.9 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl->paddlenlp) (3.8.2)
Requirement already satisfied, skipping upgrade: Pillow>=7.0.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl->paddlenlp) (7.1.2)
Requirement already satisfied, skipping upgrade: shellcheck-py in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl->paddlenlp) (0.7.1.1)
Requirement already satisfied, skipping upgrade: bce-python-sdk in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl->paddlenlp) (0.8.53)
Requirement already satisfied, skipping upgrade: protobuf>=3.11.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl->paddlenlp) (3.14.0)
Requirement already satisfied, skipping upgrade: flask>=1.1.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl->paddlenlp) (1.1.1)
Requirement already satisfied, skipping upgrade: joblib>=0.11 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from scikit-learn>=0.21.3->seqeval->paddlenlp) (0.14.1)
Requirement already satisfied, skipping upgrade: scipy>=0.19.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from scikit-learn>=0.21.3->seqeval->paddlenlp) (1.6.3)
Requirement already satisfied, skipping upgrade: threadpoolctl>=2.0.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from scikit-learn>=0.21.3->seqeval->paddlenlp) (2.1.0)
Requirement already satisfied, skipping upgrade: Babel>=2.3 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from Flask-Babel>=1.0.0->visualdl->paddlenlp) (2.8.0)
Requirement already satisfied, skipping upgrade: Jinja2>=2.5 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from Flask-Babel>=1.0.0->visualdl->paddlenlp) (2.10.1)
Requirement already satisfied, skipping upgrade: pytz in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from Flask-Babel>=1.0.0->visualdl->paddlenlp) (2019.3)
Requirement already satisfied, skipping upgrade: toml in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pre-commit->visualdl->paddlenlp) (0.10.0)
Requirement already satisfied, skipping upgrade: importlib-metadata; python_version < "3.8" in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pre-commit->visualdl->paddlenlp) (0.23)
Requirement already satisfied, skipping upgrade: identify>=1.0.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pre-commit->visualdl->paddlenlp) (1.4.10)
Requirement already satisfied, skipping upgrade: virtualenv>=15.2 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pre-commit->visualdl->paddlenlp) (16.7.9)
Requirement already satisfied, skipping upgrade: pyyaml in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pre-commit->visualdl->paddlenlp) (5.1.2)
Requirement already satisfied, skipping upgrade: nodeenv>=0.11.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pre-commit->visualdl->paddlenlp) (1.3.4)
Requirement already satisfied, skipping upgrade: cfgv>=2.0.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pre-commit->visualdl->paddlenlp) (2.0.1)
Requirement already satisfied, skipping upgrade: aspy.yaml in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pre-commit->visualdl->paddlenlp) (1.3.0)
Requirement already satisfied, skipping upgrade: chardet<3.1.0,>=3.0.2 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from requests->visualdl->paddlenlp) (3.0.4)
Requirement already satisfied, skipping upgrade: idna<2.9,>=2.5 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from requests->visualdl->paddlenlp) (2.8)
Requirement already satisfied, skipping upgrade: certifi>=2017.4.17 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from requests->visualdl->paddlenlp) (2019.9.11)
Requirement already satisfied, skipping upgrade: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from requests->visualdl->paddlenlp) (1.25.6)
Requirement already satisfied, skipping upgrade: pycodestyle<2.7.0,>=2.6.0a1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from flake8>=3.7.9->visualdl->paddlenlp) (2.6.0)
Requirement already satisfied, skipping upgrade: mccabe<0.7.0,>=0.6.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from flake8>=3.7.9->visualdl->paddlenlp) (0.6.1)
Requirement already satisfied, skipping upgrade: pyflakes<2.3.0,>=2.2.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from flake8>=3.7.9->visualdl->paddlenlp) (2.2.0)
Requirement already satisfied, skipping upgrade: pycryptodome>=3.8.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from bce-python-sdk->visualdl->paddlenlp) (3.9.9)
Requirement already satisfied, skipping upgrade: future>=0.6.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from bce-python-sdk->visualdl->paddlenlp) (0.18.0)
Requirement already satisfied, skipping upgrade: Werkzeug>=0.15 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from flask>=1.1.1->visualdl->paddlenlp) (0.16.0)
Requirement already satisfied, skipping upgrade: itsdangerous>=0.24 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from flask>=1.1.1->visualdl->paddlenlp) (1.1.0)
Requirement already satisfied, skipping upgrade: click>=5.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from flask>=1.1.1->visualdl->paddlenlp) (7.0)
Requirement already satisfied, skipping upgrade: MarkupSafe>=0.23 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from Jinja2>=2.5->Flask-Babel>=1.0.0->visualdl->paddlenlp) (1.1.1)
Requirement already satisfied, skipping upgrade: zipp>=0.5 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from importlib-metadata; python_version < "3.8"->pre-commit->visualdl->paddlenlp) (0.6.0)
Requirement already satisfied, skipping upgrade: more-itertools in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from zipp>=0.5->importlib-metadata; python_version < "3.8"->pre-commit->visualdl->paddlenlp) (7.2.0)
Installing collected packages: paddlenlp
Found existing installation: paddlenlp 2.0.1
Uninstalling paddlenlp-2.0.1:
Successfully uninstalled paddlenlp-2.0.1
Successfully installed paddlenlp-2.0.3
/home/aistudio/event_extraction
该比赛有两个子任务,一个篇章级事件抽取任务,一个句子级事件抽取任务。
篇章级事件抽取基线
篇章级事件抽取数据集(DuEE-Fin)是金融领域篇章级别事件抽取数据集, 共包含13个已定义好的事件类型约束和1.15万中文篇章(存在部分非目标篇章作为负样例),其中6900训练集,1150验证集和3450测试集,数据集下载地址 。 在该数据集上基线采用基于ERNIE的序列标注(sequence labeling)方案,分为基于序列标注的触发词抽取模型、基于序列标注的论元抽取模型和枚举属性分类模型,属于PipeLine模型;基于序列标注的触发词抽取模型采用BIO方式,识别触发词的位置以及对应的事件类型,基于序列标注的论元抽取模型采用BIO方式识别出事件中的论元以及对应的论元角色;枚举属性分类模型采用ernie进行分类。
评测方法
本任务采用预测论元F1值作为评价指标,对于每个篇章,采用不放回的方式给每个目标事件寻找最相似的预测事件(事件级别匹配),搜寻方式是优先寻找与目标事件的事件类型相同且角色和论元正确数量最多的预测事件
f1_score = (2 * P * R) / (P + R),其中
- 预测论元正确=事件类型和角色相同且论元正确
- P=预测论元正确数量 / 所有预测论元的数量
- R=预测论元正确数量 / 所有人工标注论元的数量
快速复现基线Step1:数据预处理并加载
从比赛官网下载数据集,解压存放于data/DuEE-Fin目录下,将原始数据预处理成序列标注格式数据。 处理之后的数据同样放在data/DuEE-Fin下, 触发词识别数据文件存放在data/DuEE-Fin/role下, 论元角色识别数据文件存放在data/DuEE-Fin/trigger下。 枚举分类数据存放在data/DuEE-Fin/enum下。
查看下数据role、trigger、enum格式以及下面处理时需要用到的schema.json的样式!head -2 ./data/DuEE-Fin/role/train.tsv
!head -2 ./data/DuEE-Fin/trigger/train.tsv
!head -2 ./data/DuEE-Fin/enum/train.tsv
!cat ./conf/DuEE-Fin/event_schema.json
text_a label
原标题:万讯自控(7.490,-0.10,-1.32%):傅宇晨解除部分股份质押、累计质押比例为39.55%,,,,来源:每日经济新闻,每经ai快讯,万讯自控(sz,300112,收盘价:7.49元)6月3日下午发布公告称,公司接到股东傅宇晨的通知,获悉傅宇晨将其部分股份办理了质押业务。,截至本公告日,傅宇晨共持有公司股份5790.38万股,占公司总股本的20.25%;累计质押股份2290万股,占傅宇晨持有公司股份总数的39.55%,占公司总股本的8.01%。 OOOOB-质押物所属公司I-质押物所属公司I-质押物所属公司I-质押物所属公司OOOOOOOOOOOOOOOOOOOOOB-质押方I-质押方I-质押方OOOOB-质押物I-质押物OOOOOOOOOOB-质押物占持股比I-质押物占持股比I-质押物占持股比I-质押物占持股比I-质押物占持股比I-质押物占持股比OOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOB-披露时间I-披露时间I-披露时间I-披露时间I-披露时间I-披露时间OOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOB-事件时间I-事件时间I-事件时间I-事件时间I-事件时间I-事件时间OOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOB-质押股票/股份数量I-质押股票/股份数量I-质押股票/股份数量I-质押股票/股份数量I-质押股票/股份数量OOOOOOOOOOOOOOOOOOOOOOOOOOOOOB-质押物占总股比I-质押物占总股比I-质押物占总股比I-质押物占总股比I-质押物占总股比O
text_a label
原标题:万讯自控(7.490,-0.10,-1.32%):傅宇晨解除部分股份质押、累计质押比例为39.55%,,,,来源:每日经济新闻,每经ai快讯,万讯自控(sz,300112,收盘价:7.49元)6月3日下午发布公告称,公司接到股东傅宇晨的通知,获悉傅宇晨将其部分股份办理了质押业务。,截至本公告日,傅宇晨共持有公司股份5790.38万股,占公司总股本的20.25%;累计质押股份2290万股,占傅宇晨持有公司股份总数的39.55%,占公司总股本的8.01%。 OOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOB-质押I-质押OOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOO
label text_a
正式上市 北京博睿宏远数据科技股份有限公司首次公开发行股票并在科创板上市发行公告
{"role_list": [{"role": "质押方"}, {"role": "披露时间"}, {"role": "质权方"}, {"role": "质押物"}, {"role": "质押股票/股份数量"}, {"role": "事件时间"}, {"role": "质押物所属公司"}, {"role": "质押物占总股比"}, {"role": "质押物占持股比"}], "event_type": "解除质押", "id": "66fd6541f6e81ecbc9df69ac377d8d8f"}
{"role_list": [{"role": "回购方"}, {"role": "披露时间"}, {"role": "回购股份数量"}, {"role": "每股交易价格"}, {"role": "占公司总股本比例"}, {"role": "交易金额"}, {"role": "回购完成时间"}], "event_type": "股份回购", "id": "ce7923d3e82610c3f1692f98193426d6"}
{"role_list": [{"role": "股票简称"}, {"role": "披露时间"}, {"role": "交易股票/股份数量"}, {"role": "每股交易价格"}, {"role": "交易金额"}, {"role": "交易完成时间"}, {"role": "减持方"}, {"role": "减持部分占所持比例"}, {"role": "减持部分占总股本比例"}], "event_type": "股东减持", "id": "42774ed6cc845ce2bbcbce242deb8994"}
{"role_list": [{"role": "公司名称"}, {"role": "披露时间"}, {"role": "财报周期"}, {"role": "净亏损"}, {"role": "亏损变化"}], "event_type": "亏损", "id": "83c21d96a46a78c2e3620fd75668675d"}
{"role_list": [{"role": "中标公司"}, {"role": "中标标的"}, {"role": "中标金额"}, {"role": "招标方"}, {"role": "中标日期"}, {"role": "披露日期"}], "event_type": "中标", "id": "90faa2088d198f670edbb6dc65766877"}
{"role_list": [{"role": "高管姓名"}, {"role": "任职公司"}, {"role": "高管职位"}, {"role": "事件时间"}, {"role": "变动类型"}, {"role": "披露日期"}, {"role": "变动后职位"}, {"role": "变动后公司名称"}], "event_type": "高管变动", "id": "2f2acf626f0e06df3f0491ff37db2b3e"}
{"role_list": [{"role": "破产公司"}, {"role": "披露时间"}, {"role": "债务规模"}, {"role": "破产时间"}, {"role": "债权人"}], "event_type": "企业破产", "id": "2fbbd5f1cebf47c246249880d283bcbe"}
{"role_list": [{"role": "股票简称"}, {"role": "披露时间"}, {"role": "交易股票/股份数量"}, {"role": "每股交易价格"}, {"role": "交易金额"}, {"role": "交易完成时间"}, {"role": "增持方"}, {"role": "增持部分占所持比例"}, {"role": "增持部分占总股本比例"}], "event_type": "股东增持", "id": "4dc69ee28203586370682f470c1d7adb"}
{"role_list": [{"role": "公司名称"}, {"role": "披露时间"}, {"role": "被约谈时间"}, {"role": "约谈机构"}], "event_type": "被约谈", "id": "9e643c132a375d01de6c8f84b03bfcfe"}
{"role_list": [{"role": "收购方"}, {"role": "披露时间"}, {"role": "被收购方"}, {"role": "收购标的"}, {"role": "交易金额"}, {"role": "收购完成时间"}], "event_type": "企业收购", "id": "f0cd6c0317f6c938d9906b91eead9a34"}
{"role_list": [{"role": "上市公司"}, {"role": "证券代码"}, {"enum_items": ["筹备上市", "暂停上市", "正式上市", "终止上市"], "role": "环节"}, {"role": "披露时间"}, {"role": "发行价格"}, {"role": "事件时间"}, {"role": "市值"}, {"role": "募资金额"}], "event_type": "公司上市", "id": "0bb90bf676836936f8d687513114b454"}
{"role_list": [{"role": "投资方"}, {"role": "披露时间"}, {"role": "被投资方"}, {"role": "融资金额"}, {"role": "融资轮次"}, {"role": "事件时间"}, {"role": "领投方"}], "event_type": "企业融资", "id": "c539448a3c5ba9555a6084296ad98a19"}
{"role_list": [{"role": "质押方"}, {"role": "披露时间"}, {"role": "质权方"}, {"role": "质押物"}, {"role": "质押股票/股份数量"}, {"role": "事件时间"}, {"role": "质押物占总股比"}, {"role": "质押物所属公司"}, {"role": "质押物占持股比"}], "event_type": "质押", "id": "71cd7c375ab7a93fc82e415a285e9579"}
:阅读run_duee_fin.sh可见,参数data_prepare使得其运行了python duee_fin_data_prepare.py:
- duee_fin_data_prepare.py代码首先处理了
./conf/DuEE-Fin/event_schema.json文件,并将其处理为:- ./conf/DuEE-Fin/trigger_tag.dict
- ./conf/DuEE-Fin/enum_tag.dict
- ./conf/DuEE-Fin/role_tag.dict 三个文件
- duee_fin_data_prepare.py代码其次处理了
./data/DuEE-Fin/文件夹内的数据,处理方式 (此步骤生成了sentence文件夹) :duee_fin_train.json处理为./data/DuEE-Fin/sentence/train.jsonduee_fin_dev.json处理为./data/DuEE-Fin/sentence/dev.jsonduee_fin_test1.json处理为./data/DuEE-Fin/sentence/test.json
- duee_fin_data_prepare.py代码再次处理了
./data/DuEE-Fin/sentence/文件夹内的数据,处理方式 (此步骤生成了trigger文件夹) :train.json处理为./data/DuEE-Fin/trigger/train.tsvdev.json处理为./data/DuEE-Fin/trigger/dev.tsvtest.json处理为./data/DuEE-Fin/trigger/test.tsv
- duee_fin_data_prepare.py代码接着处理了
./data/DuEE-Fin/sentence/文件夹内的数据,处理方式 (此步骤生成了role文件夹) :train.json处理为./data/DuEE-Fin/role/train.tsvdev.json处理为./data/DuEE-Fin/role/dev.tsvtest.json处理为./data/DuEE-Fin/role/test.tsv
- duee_fin_data_prepare.py代码最后处理了
./data/DuEE-Fin/sentence/文件夹内的数据,处理方式 (此步骤生成了enum文件夹) :train.json处理为./data/DuEE-Fin/enum/train.tsvdev.json处理为./data/DuEE-Fin/enum/dev.tsvtest.json处理为./data/DuEE-Fin/enum/test.tsv
!bash ./run_duee_fin.sh data_prepare
check and create directory
dir ./ckpt exist
dir ./ckpt/DuEE-Fin exist
dir ./submit exist
start DuEE-Fin data prepare
=================DUEE FINANCE DATASET==============
=================start schema process==============
input path ./conf/DuEE-Fin/event_schema.json
save trigger tag 27 at ./conf/DuEE-Fin/trigger_tag.dict
save trigger tag 121 at ./conf/DuEE-Fin/role_tag.dict
save enum tag 4 at ./conf/DuEE-Fin/enum_tag.dict
=================end schema process===============
=================start data process==============
********** start document process **********
train 32795 dev 5302 test 140867
********** end document process **********
********** start sentence process **********
----trigger------for dir ./data/DuEE-Fin/sentence to ./data/DuEE-Fin/trigger
train 7251 dev 1180
----role------for dir ./data/DuEE-Fin/sentence to ./data/DuEE-Fin/role
train 9441 dev 1524
----enum------for dir ./data/DuEE-Fin/sentence to ./data/DuEE-Fin/enum
train 429 dev 69
********** end sentence process **********
=================end data process==============
end DuEE-Fin data prepare
查看生成的数据字典格式
!echo ">>>>>>>>>>>> trigger_tag.dict <<<<<<<<<<<<<"
!cat ./conf/DuEE-Fin/trigger_tag.dict #对应./conf/DuEE-Fin/event_schema.json文件中'event_type'键的值
!echo ">>>>>>>>>>>>> enum_tag.dict <<<<<<<<<<<<<"
!cat ./conf/DuEE-Fin/enum_tag.dict #对应./conf/DuEE-Fin/event_schema.json文件中'enum_items'键的值
!echo ">>>>>>>>>>>>> role_tag.dict <<<<<<<<<<<<<"
!cat ./conf/DuEE-Fin/role_tag.dict #对应./conf/DuEE-Fin/event_schema.json文件中'role'键的值
>>>>>>>>>>>> trigger_tag.dict <<<<<<<<<<<<<
0 B-解除质押
1 I-解除质押
2 B-股份回购
3 I-股份回购
4 B-股东减持
5 I-股东减持
6 B-亏损
7 I-亏损
8 B-中标
9 I-中标
10 B-高管变动
11 I-高管变动
12 B-企业破产
13 I-企业破产
14 B-股东增持
15 I-股东增持
16 B-被约谈
17 I-被约谈
18 B-企业收购
19 I-企业收购
20 B-公司上市
21 I-公司上市
22 B-企业融资
23 I-企业融资
24 B-质押
25 I-质押
26 O
>>>>>>>>>>>>> enum_tag.dict <<<<<<<<<<<<<
0 筹备上市
1 暂停上市
2 正式上市
3 终止上市
>>>>>>>>>>>>> role_tag.dict <<<<<<<<<<<<<
0 B-质押方
1 I-质押方
2 B-披露时间
3 I-披露时间
4 B-质权方
5 I-质权方
6 B-质押物
7 I-质押物
8 B-质押股票/股份数量
9 I-质押股票/股份数量
10 B-事件时间
11 I-事件时间
12 B-质押物所属公司
13 I-质押物所属公司
14 B-质押物占总股比
15 I-质押物占总股比
16 B-质押物占持股比
17 I-质押物占持股比
18 B-回购方
19 I-回购方
20 B-回购股份数量
21 I-回购股份数量
22 B-每股交易价格
23 I-每股交易价格
24 B-占公司总股本比例
25 I-占公司总股本比例
26 B-交易金额
27 I-交易金额
28 B-回购完成时间
29 I-回购完成时间
30 B-股票简称
31 I-股票简称
32 B-交易股票/股份数量
33 I-交易股票/股份数量
34 B-交易完成时间
35 I-交易完成时间
36 B-减持方
37 I-减持方
38 B-减持部分占所持比例
39 I-减持部分占所持比例
40 B-减持部分占总股本比例
41 I-减持部分占总股本比例
42 B-公司名称
43 I-公司名称
44 B-财报周期
45 I-财报周期
46 B-净亏损
47 I-净亏损
48 B-亏损变化
49 I-亏损变化
50 B-中标公司
51 I-中标公司
52 B-中标标的
53 I-中标标的
54 B-中标金额
55 I-中标金额
56 B-招标方
57 I-招标方
58 B-中标日期
59 I-中标日期
60 B-披露日期
61 I-披露日期
62 B-高管姓名
63 I-高管姓名
64 B-任职公司
65 I-任职公司
66 B-高管职位
67 I-高管职位
68 B-变动类型
69 I-变动类型
70 B-变动后职位
71 I-变动后职位
72 B-变动后公司名称
73 I-变动后公司名称
74 B-破产公司
75 I-破产公司
76 B-债务规模
77 I-债务规模
78 B-破产时间
79 I-破产时间
80 B-债权人
81 I-债权人
82 B-增持方
83 I-增持方
84 B-增持部分占所持比例
85 I-增持部分占所持比例
86 B-增持部分占总股本比例
87 I-增持部分占总股本比例
88 B-被约谈时间
89 I-被约谈时间
90 B-约谈机构
91 I-约谈机构
92 B-收购方
93 I-收购方
94 B-被收购方
95 I-被收购方
96 B-收购标的
97 I-收购标的
98 B-收购完成时间
99 I-收购完成时间
100 B-上市公司
101 I-上市公司
102 B-证券代码
103 I-证券代码
104 B-发行价格
105 I-发行价格
106 B-市值
107 I-市值
108 B-募资金额
109 I-募资金额
110 B-投资方
111 I-投资方
112 B-被投资方
113 I-被投资方
114 B-融资金额
115 I-融资金额
116 B-融资轮次
117 I-融资轮次
118 B-领投方
119 I-领投方
120 O
根据下面一块代码中数据集加载的路径./data/DuEE-Fin/trigger/可知,下面开始的代码直到!bash run_duee_fin.sh trigger_predict这行脚本代码前的运行过程,等价于该行脚本代码!bash run_duee_fin.sh trigger_predict的执行结果(除了训练配置参数不同)。
我们可以加载自定义数据集。通过继承paddle.io.Dataset,自定义实现__getitem__ 和 __len__两个方法。
如完成触发词识别,加载数据集event_extraction/data/DuEE-Fin/trigger。
import paddle
from utils import load_dict
class DuEventExtraction(paddle.io.Dataset): #对应于sequence_labeling.py文件中的DuEventExtraction类
"""DuEventExtraction"""
def __init__(self, data_path, tag_path):
self.label_vocab = load_dict(tag_path)
self.word_ids = []
self.label_ids = []
with open(data_path, 'r', encoding='utf-8') as fp:
# skip the head line
next(fp)
for line in fp.readlines():
words, labels = line.strip('\n').split('\t')
words = words.split('\002')
labels = labels.split('\002')
self.word_ids.append(words)
self.label_ids.append(labels)
self.label_num = max(self.label_vocab.values()) + 1
def __len__(self):
return len(self.word_ids)
def __getitem__(self, index):
return self.word_ids[index], self.label_ids[index]
train_ds = DuEventExtraction('./data/DuEE-Fin/trigger/train.tsv', './conf/DuEE-Fin/trigger_tag.dict')
dev_ds = DuEventExtraction('./data/DuEE-Fin/trigger/dev.tsv', './conf/DuEE-Fin/trigger_tag.dict')
count = 0
for text, label in train_ds:
print(f"text: {text}; label: {label}")
count += 1
if count >= 3:
break
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:26: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information.
Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
def convert_to_list(value, n, name, dtype=np.int):
text: ['原', '标', '题', ':', '万', '讯', '自', '控', '(', '7', '.', '4', '9', '0', ',', '-', '0', '.', '1', '0', ',', '-', '1', '.', '3', '2', '%', ')', ':', '傅', '宇', '晨', '解', '除', '部', '分', '股', '份', '质', '押', '、', '累', '计', '质', '押', '比', '例', '为', '3', '9', '.', '5', '5', '%', ',', ',', ',', ',', '来', '源', ':', '每', '日', '经', '济', '新', '闻', ',', '每', '经', 'a', 'i', '快', '讯', ',', '万', '讯', '自', '控', '(', 's', 'z', ',', '3', '0', '0', '1', '1', '2', ',', '收', '盘', '价', ':', '7', '.', '4', '9', '元', ')', '6', '月', '3', '日', '下', '午', '发', '布', '公', '告', '称', ',', '公', '司', '接', '到', '股', '东', '傅', '宇', '晨', '的', '通', '知', ',', '获', '悉', '傅', '宇', '晨', '将', '其', '部', '分', '股', '份', '办', '理', '了', '质', '押', '业', '务', '。', ',', '截', '至', '本', '公', '告', '日', ',', '傅', '宇', '晨', '共', '持', '有', '公', '司', '股', '份', '5', '7', '9', '0', '.', '3', '8', '万', '股', ',', '占', '公', '司', '总', '股', '本', '的', '2', '0', '.', '2', '5', '%', ';', '累', '计', '质', '押', '股', '份', '2', '2', '9', '0', '万', '股', ',', '占', '傅', '宇', '晨', '持', '有', '公', '司', '股', '份', '总', '数', '的', '3', '9', '.', '5', '5', '%', ',', '占', '公', '司', '总', '股', '本', '的', '8', '.', '0', '1', '%', '。']; label: ['O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'B-质押', 'I-质押', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O']
text: ['客', '户', '端', ',', '新', '浪', '港', '股', '讯', ',', '众', '安', '集', '团', '(', '0', '.', '2', '4', '8', ',', '-', '0', '.', '0', '0', ',', '-', '0', '.', '8', '0', '%', ')', '(', '0', '0', '6', '7', '2', '.', 'h', 'k', ')', '发', '布', '公', '告', ',', '于', '2', '0', '1', '9', '年', '1', '0', '月', '1', '5', '日', ',', '公', '司', '耗', '资', '9', '4', '.', '5', '6', '万', '港', '元', '回', '购', '3', '8', '0', '.', '5', '万', '股', ',', '回', '购', '价', '格', '每', '股', '0', '.', '2', '4', '8', '-', '0', '.', '2', '4', '9', '港', '元', '。']; label: ['O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'B-股份回购', 'I-股份回购', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O']
text: ['原', '标', '题', ':', '金', '徽', '酒', '(', '6', '0', '3', '9', '1', '9', '.', 's', 'h', ')', ':', '亚', '特', '集', '团', '解', '除', '质', '押', '1', '9', '8', '0', '万', '股', ',', ',', ',', ',', '来', '源', ':', '格', '隆', '汇', ',', '格', '隆', '汇', '8', '月', '5', '日', '丨', '金', '徽', '酒', '(', '6', '0', '3', '9', '1', '9', '.', 's', 'h', ')', '公', '布', ',', '公', '司', '近', '日', '收', '到', '控', '股', '股', '东', '甘', '肃', '亚', '特', '投', '资', '集', '团', '有', '限', '公', '司', '(', '“', '亚', '特', '集', '团', '”', ')', '将', '其', '持', '有', '的', '公', '司', '部', '分', '股', '份', '解', '除', '质', '押', '的', '通', '知', '。', ',', '2', '0', '1', '8', '年', '4', '月', '9', '日', ',', '亚', '特', '集', '团', '将', '其', '持', '有', '的', '公', '司', '5', '9', '8', '0', '万', '股', '有', '限', '售', '条', '件', '股', '份', '质', '押', '给', '兰', '州', '银', '行', '股', '份', '有', '限', '公', '司', '陇', '南', '分', '行', '。']; label: ['O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'B-解除质押', 'I-解除质押', 'I-解除质押', 'I-解除质押', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O']
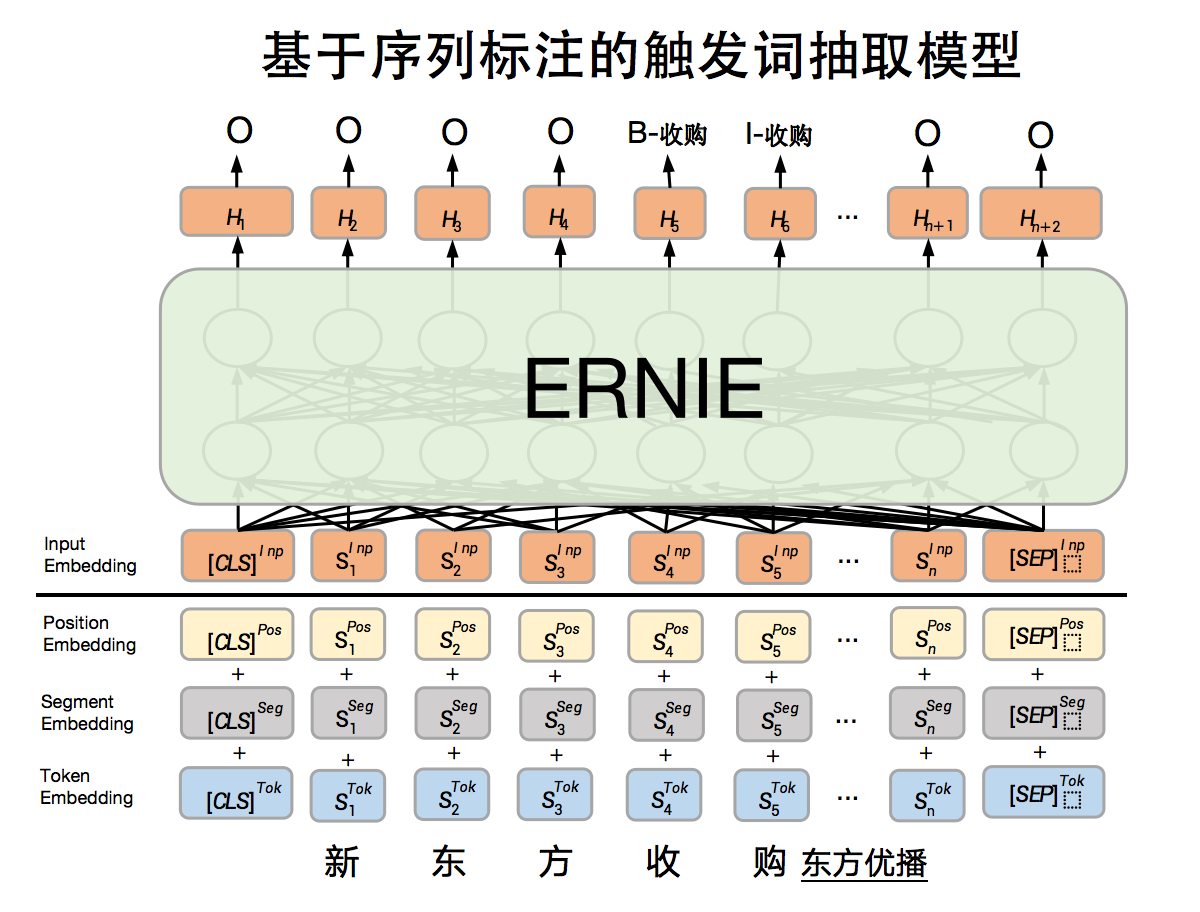
快速复现基线Step2:构建模型
基于序列标注的触发词抽取模型是整体模型的一部分,该部分主要是给定事件类型,识别句子中出现的事件触发词对应的位置以及对应的事件类别,该模型是基于ERNIE开发序列标注模型,模型原理图如下:
同样地,基于序列标注的论元抽取模型也是基于ERNIE开发序列标注模型,该部分主要是识别出事件中的论元以及对应论元角色,模型原理图如下:
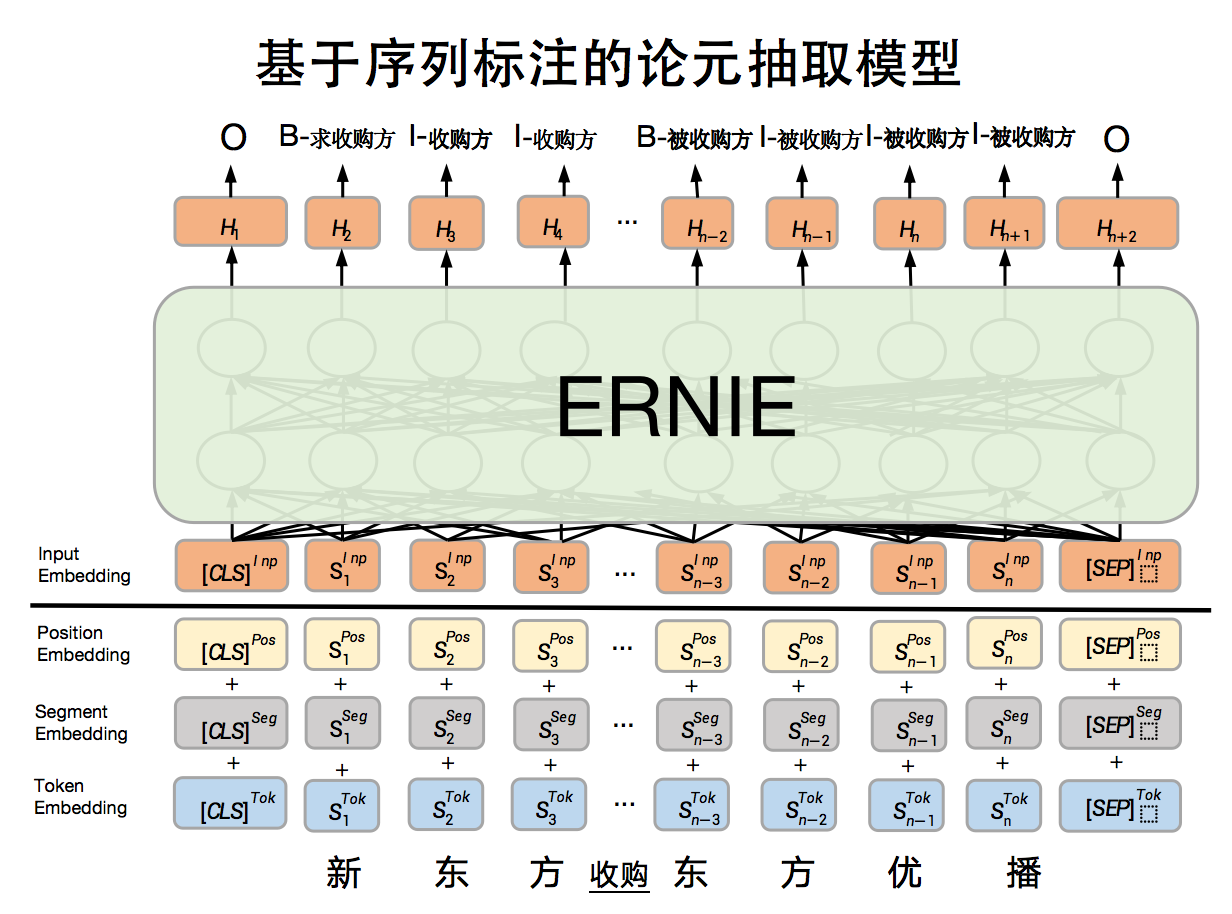
上述样例中通过模型识别出:1)论元”新东方”,并分配标签”B-收购方”、”I-收购方”、”I-收购方”;2)论元”东方优播”, 并分配标签”B-被收购方”、”I-被收购方”、”I-被收购方”、”I-被收购方”。最终识别出文本中包含的论元角色和论元对是<收购方,新东方>、<被收购方,东方优播>
PaddleNLP提供了ERNIE预训练模型常用序列标注模型,可以通过指定模型名字完成一键加载:
from paddlenlp.transformers import ErnieForTokenClassification, ErnieForSequenceClassification
label_map = load_dict('./conf/DuEE-Fin/trigger_tag.dict')
id2label = {val: key for key, val in label_map.items()}
model = ErnieForTokenClassification.from_pretrained("ernie-1.0", num_classes=len(label_map))
[2021-06-23 10:41:24,076] [ INFO] - Downloading https://paddlenlp.bj.bcebos.com/models/transformers/ernie/ernie_v1_chn_base.pdparams and saved to /home/aistudio/.paddlenlp/models/ernie-1.0
[2021-06-23 10:41:24,079] [ INFO] - Downloading ernie_v1_chn_base.pdparams from https://paddlenlp.bj.bcebos.com/models/transformers/ernie/ernie_v1_chn_base.pdparams
100%|██████████| 392507/392507 [00:06<00:00, 62564.18it/s]
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py:1303: UserWarning: Skip loading for classifier.weight. classifier.weight is not found in the provided dict.
warnings.warn(("Skip loading for {}. ".format(key) + str(err)))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py:1303: UserWarning: Skip loading for classifier.bias. classifier.bias is not found in the provided dict.
warnings.warn(("Skip loading for {}. ".format(key) + str(err)))
同时,对于枚举分类数据采用的是基于ERNIE的文本分类模型,枚举角色类型为环节。模型原理图如下:
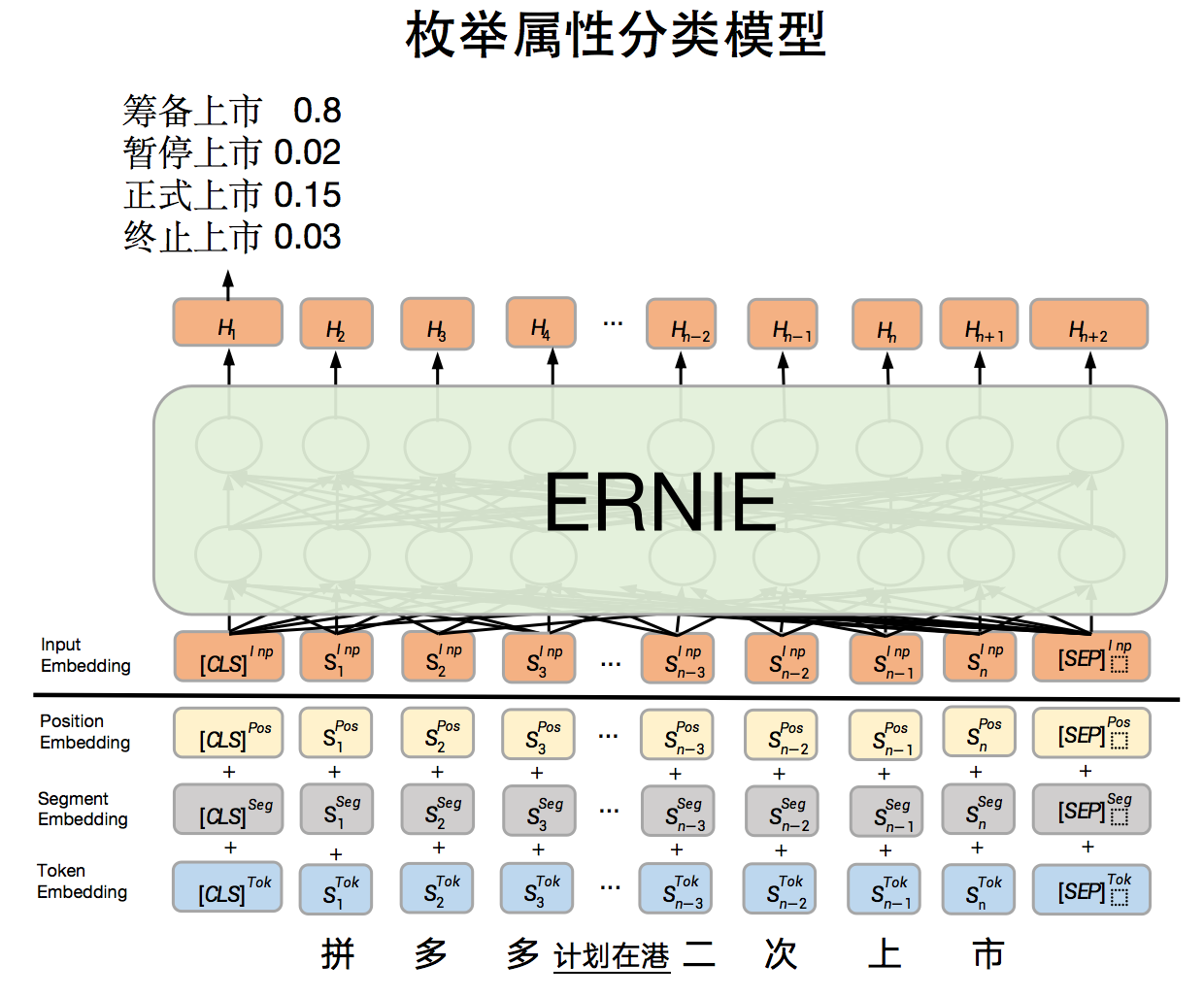
给定文本,对文本进行分类,得到不同类别上的概率 筹备上市(0.8)、暂停上市(0.02)、正式上市(0.15)、终止上市(0.03)
同样地,PaddleNLP提供了ERNIE预训练模型常用文本分类模型,可以通过指定模型名字完成一键加载:
from paddlenlp.transformers import ErnieForSequenceClassification
model = ErnieForSequenceClassification.from_pretrained("ernie-1.0", num_classes=len(label_map))
快速复现基线Step3:数据处理
我们需要将原始数据处理成模型可读入的数据。PaddleNLP为了方便用户处理数据,内置了对于各个预训练模型对应的Tokenizer,可以完成 文本token化,转token ID,文本长度截断等操作。与加载模型类似地,也可以一键加载。
文本数据处理直接调用tokenizer即可输出模型所需输入数据。
from paddlenlp.transformers import ErnieTokenizer, ErnieModel
tokenizer = ErnieTokenizer.from_pretrained("ernie-1.0")
ernie_model = ErnieModel.from_pretrained("ernie-1.0")
# 一行代码完成切分token,映射token ID以及拼接特殊token
encoded_text = tokenizer(text="请输入测试样例", return_length=True, return_position_ids=True)
for key, value in encoded_text.items():
print("{}:\n\t{}".format(key, value))
# 转化成paddle框架数据格式
input_ids = paddle.to_tensor([encoded_text['input_ids']])
print("input_ids : \n\t{}".format(input_ids))
segment_ids = paddle.to_tensor([encoded_text['token_type_ids']])
print("token_type_ids : \n\t{}".format(segment_ids))
# 此时即可输入ERNIE模型中得到相应输出
sequence_output, pooled_output = ernie_model(input_ids, segment_ids)
print("Token wise output shape: \n\t{}\nPooled output shape: \n\t{}".format(sequence_output.shape, pooled_output.shape))
[2021-06-23 10:42:19,204] [ INFO] - Downloading vocab.txt from https://paddlenlp.bj.bcebos.com/models/transformers/ernie/vocab.txt
100%|██████████| 90/90 [00:00<00:00, 18476.21it/s]
[2021-06-23 10:42:19,258] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/ernie-1.0/ernie_v1_chn_base.pdparams
[2021-06-23 10:42:20,324] [ INFO] - Weights from pretrained model not used in ErnieModel: ['cls.predictions.layer_norm.weight', 'cls.predictions.decoder_bias', 'cls.predictions.transform.bias', 'cls.predictions.transform.weight', 'cls.predictions.layer_norm.bias']
input_ids:
[1, 647, 789, 109, 558, 525, 314, 656, 2]
token_type_ids:
[0, 0, 0, 0, 0, 0, 0, 0, 0]
seq_len:
9
position_ids:
[0, 1, 2, 3, 4, 5, 6, 7, 8]
input_ids :
Tensor(shape=[1, 9], dtype=int64, place=CUDAPlace(0), stop_gradient=True,
[[1 , 647, 789, 109, 558, 525, 314, 656, 2 ]])
token_type_ids :
Tensor(shape=[1, 9], dtype=int64, place=CUDAPlace(0), stop_gradient=True,
[[0, 0, 0, 0, 0, 0, 0, 0, 0]])
Token wise output shape:
[1, 9, 768]
Pooled output shape:
[1, 768]
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/tensor/creation.py:143: DeprecationWarning: `np.object` is a deprecated alias for the builtin `object`. To silence this warning, use `object` by itself. Doing this will not modify any behavior and is safe.
Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
if data.dtype == np.object:
由以上代码可以见,tokenizer提供了一种非常便利的方式生成模型所需的数据格式。
以上,
- input_ids: 表示输入文本的token ID。
- token_type_ids: 表示对应的token属于输入的第一个句子还是第二个句子。(Transformer类预训练模型支持单句以及句对输入。)详细参见左侧 sequence_labeling.py convert_example_to_feature()函数解释。
- seq_len: 表示输入句子的token个数。
- input_mask:表示对应的token是否一个padding token。由于一个batch中的输入句子长度不同,所以需要将不同长度的句子padding到统一固定长度。1表示真实输入,0表示对应token为padding token。
- position_ids: 表示对应token在整个输入序列中的位置。
同时,ERNIE模型输出有2个tensor。
- sequence_output是对应每个输入token的语义特征表示,shape为(1, num_tokens, hidden_size)。其一般用于序列标注、问答等任务。
- pooled_output是对应整个句子的语义特征表示,shape为(1, hidden_size)。其一般用于文本分类、信息检索等任务。
NOTE:
如需使用ernie-tiny预训练模型,则对应的tokenizer应该使用paddlenlp.transformers.ErnieTinyTokenizer.from_pretrained('ernie-tiny')
以上代码示例展示了使用Transformer类预训练模型所需的数据处理步骤。为了更方便地使用,PaddleNLP同时提供了更加高阶API,一键即可返回模型所需数据格式。
本基线将对数据作以下处理:
- 将原始数据处理成模型可以读入的格式。首先使用tokenizer切词并映射词表中input ids,转化token type ids等。
- 使用paddle.io.DataLoader接口多进程异步加载数据。
from functools import partial
from paddlenlp.data import Stack, Tuple, Pad
def convert_example_to_feature(example, tokenizer, label_vocab=None, max_seq_len=512, no_entity_label="O", ignore_label=-1, is_test=False):
tokens, labels = example
tokenized_input = tokenizer(
tokens,
return_length=True,
is_split_into_words=True,
max_seq_len=max_seq_len)
input_ids = tokenized_input['input_ids']
token_type_ids = tokenized_input['token_type_ids']
seq_len = tokenized_input['seq_len']
if is_test:
return input_ids, token_type_ids, seq_len
elif label_vocab is not None:
labels = labels[:(max_seq_len-2)]
encoded_label = [no_entity_label] + labels + [no_entity_label]
encoded_label = [label_vocab[x] for x in encoded_label]
return input_ids, token_type_ids, seq_len, encoded_label
no_entity_label = "O"
# padding label value
ignore_label = -1
batch_size = 4
max_seq_len = 300
trans_func = partial(
convert_example_to_feature,
tokenizer=tokenizer,
label_vocab=train_ds.label_vocab,
max_seq_len=max_seq_len,
no_entity_label=no_entity_label,
ignore_label=ignore_label,
is_test=False)
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.vocab[tokenizer.pad_token]), # input ids
Pad(axis=0, pad_val=tokenizer.vocab[tokenizer.pad_token]), # token type ids
Stack(), # sequence lens
Pad(axis=0, pad_val=ignore_label) # labels
): fn(list(map(trans_func, samples)))
train_loader = paddle.io.DataLoader(
dataset=train_ds,
batch_size=batch_size,
shuffle=True,
collate_fn=batchify_fn)
dev_loader = paddle.io.DataLoader(
dataset=dev_ds,
batch_size=batch_size,
collate_fn=batchify_fn)
NOTE:
如果遇到显存不足的问题,可以调整max_seq_len和batch_size以适配显存大小。
快速复现基线Step4:定义损失函数和优化器,开始训练
在该基线上,我们选择交叉墒作为损失函数,使用paddle.optimizer.AdamW作为优化器。
import numpy as np
@paddle.no_grad()
def evaluate(model, criterion, metric, num_label, data_loader):
"""evaluate"""
model.eval()
metric.reset()
losses = []
for input_ids, seg_ids, seq_lens, labels in data_loader:
logits = model(input_ids, seg_ids)
loss = paddle.mean(criterion(logits.reshape([-1, num_label]), labels.reshape([-1])))
losses.append(loss.numpy())
preds = paddle.argmax(logits, axis=-1)
n_infer, n_label, n_correct = metric.compute(seq_lens, preds, labels)
metric.update(n_infer.numpy(), n_label.numpy(), n_correct.numpy())
precision, recall, f1_score = metric.accumulate()
avg_loss = np.mean(losses)
model.train()
return precision, recall, f1_score, avg_loss
# 模型参数保存路径
!mkdir ckpt/DuEE-Fin/trigger/
mkdir: cannot create directory ‘ckpt/DuEE-Fin/trigger/’: File exists
import warnings
from paddlenlp.metrics import ChunkEvaluator
warnings.filterwarnings('ignore')
learning_rate=5e-5
weight_decay=0.01
num_epoch = 1
checkpoints = 'ckpt/DuEE-Fin/trigger/'
num_training_steps = len(train_loader) * num_epoch
# Generate parameter names needed to perform weight decay.
# All bias and LayerNorm parameters are excluded.
decay_params = [
p.name for n, p in model.named_parameters()
if not any(nd in n for nd in ["bias", "norm"])
]
optimizer = paddle.optimizer.AdamW(
learning_rate=learning_rate,
parameters=model.parameters(),
weight_decay=weight_decay,
apply_decay_param_fun=lambda x: x in decay_params)
metric = ChunkEvaluator(label_list=train_ds.label_vocab.keys(), suffix=False)
criterion = paddle.nn.loss.CrossEntropyLoss(ignore_index=ignore_label)
step, best_f1 = 0, 0.0
model.train()
rank = paddle.distributed.get_rank()
for epoch in range(num_epoch):
for idx, (input_ids, token_type_ids, seq_lens, labels) in enumerate(train_loader):
logits = model(input_ids, token_type_ids).reshape(
[-1, train_ds.label_num])
loss = paddle.mean(criterion(logits, labels.reshape([-1])))
loss.backward()
optimizer.step()
optimizer.clear_grad()
loss_item = loss.numpy().item()
if step > 0 and step % 10 == 0 and rank == 0:
print(f'train epoch: {epoch} - step: {step} (total: {num_training_steps}) - loss: {loss_item:.6f}')
if step > 0 and step % 50 == 0 and rank == 0:
p, r, f1, avg_loss = evaluate(model, criterion, metric, len(label_map), dev_loader)
print(f'dev step: {step} - loss: {avg_loss:.5f}, precision: {p:.5f}, recall: {r:.5f}, ' \
f'f1: {f1:.5f} current best {best_f1:.5f}')
if f1 > best_f1:
best_f1 = f1
print(f'==============================================save best model ' \
f'best performerence {best_f1:5f}')
paddle.save(model.state_dict(), '{}/best.pdparams'.format(checkpoints))
step += 1
# save the final model
if rank == 0:
paddle.save(model.state_dict(), '{}/final.pdparams'.format(checkpoints))
论元识别模型训练与触发词模型训练相同,只需将数据换成处理过后的论元识别数据集即可。 可通过如下方式启动训练。
注意:训练时运行了run_sequence_labeling.sh脚本,如下句子可以看出
--train_data ${data_dir}/train.tsv \
--dev_data ${data_dir}/dev.tsv \
--test_data ${data_dir}/test.tsv \
数据默认选择的是train/dev/test.tsv,注意根据具体情况修改数据名称来训练/验证/测试!!
# 触发词识别模型训练
!bash run_duee_fin.sh trigger_train
# 触发词识别预测
!bash run_duee_fin.sh trigger_predict
# 论元识别模型训练
!bash run_duee_fin.sh role_train
# 论元识别预测
!bash run_duee_fin.sh role_predict
# 枚举分类模型训练
!bash run_duee_fin.sh enum_train
# 枚举分类预测
!bash run_duee_fin.sh enum_predict
快速复现基线Step5:数据后处理,提交结果
按照比赛预测指定格式提交结果至评测网站。
结果存放于submit/test_duee_fin.json
!bash run_duee_fin.sh pred_2_submit
check and create directory
dir ./ckpt exist
dir ./ckpt/DuEE-Fin exist
dir ./submit exist
start DuEE-Fin predict data merge to submit fotmat
trigger predict 140867 load from ./ckpt/DuEE-Fin/trigger/test_pred.json
role predict 140867 load from ./ckpt/DuEE-Fin/role/test_pred.json
enum predict 140867 load from ./ckpt/DuEE-Fin/enum/test_pred.json
schema 13 load from ./conf/DuEE-Fin/event_schema.json
submit data 30000 save to ./submit/test_duee_fin.json
end DuEE-Fin role predict data merge
句子级事件抽取基线:注意:此处开始的数据训练才千言数据集:信息抽取之——DuEE有关,如果需要训练并提交结果可以直接从这里开始,整体代码逻辑跟上面的代码处理过程没有区别
句子级别通用领域的事件抽取数据集(DuEE 1.0)上进行事件抽取的基线模型,该模型采用基于ERNIE的序列标注(sequence labeling)方案,分为基于序列标注的触发词抽取模型和基于序列标注的论元抽取模型,属于PipeLine模型;基于序列标注的触发词抽取模型采用BIO方式,识别触发词的位置以及对应的事件类型,基于序列标注的论元抽取模型采用BIO方式识别出事件中的论元以及对应的论元角色。模型和数据处理方式与篇章级事件抽取相同,此处不再赘述。句子级别通用领域的事件抽取无枚举角色分类。
# 下面的命令执行是因为原项目中的数据与【千言数据集:信息抽取】的比赛不一致————运行过一次就行了,因此现在给注释掉了。
# !unzip -o ~/data/data78774/DuEE_1_0.zip -d ~/data #解压缩DuEE的数据
# !cp ~/data/DuEE_1_0/train.json ~/event_extraction/data/DuEE1.0/ #将该数据拷贝到处理数据的文件夹内
# !cp ~/data/DuEE_1_0/dev.json ~/event_extraction/data/DuEE1.0/ #将该数据拷贝到处理数据的文件夹内
# !cp ~/data/DuEE_1_0/test.json ~/event_extraction/data/DuEE1.0/ #将该数据拷贝到处理数据的文件夹内
# !cp ~/data/DuEE_1_0/event_schema.json ~/event_extraction/data/DuEE1.0/ #将该数据拷贝到处理数据的文件夹内
Archive: /home/aistudio/data/data78774/DuEE_1_0.zip
inflating: /home/aistudio/data/DuEE_1_0/test.json
inflating: /home/aistudio/data/__MACOSX/DuEE_1_0/._test.json
inflating: /home/aistudio/data/DuEE_1_0/dev.json
inflating: /home/aistudio/data/__MACOSX/DuEE_1_0/._dev.json
inflating: /home/aistudio/data/DuEE_1_0/License.pdf
inflating: /home/aistudio/data/__MACOSX/DuEE_1_0/._License.pdf
inflating: /home/aistudio/data/DuEE_1_0/train.json
inflating: /home/aistudio/data/__MACOSX/DuEE_1_0/._train.json
inflating: /home/aistudio/data/DuEE_1_0/event_schema.json
inflating: /home/aistudio/data/__MACOSX/DuEE_1_0/._event_schema.json
inflating: /home/aistudio/data/__MACOSX/._DuEE_1_0
%cd ~/event_extraction/
# 数据预处理
!bash run_duee_1.sh data_prepare
# 训练触发词识别模型
!bash run_duee_1.sh trigger_train
# 触发词识别预测
!bash run_duee_1.sh trigger_predict
check and create directory
dir ./ckpt exist
dir ./ckpt/DuEE1.0 exist
dir ./submit exist
start DuEE1.0 trigger predict
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:26: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information.
Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
def convert_to_list(value, n, name, dtype=np.int):
[2021-06-25 16:19:53,997] [ INFO] - Found /home/aistudio/.paddlenlp/models/skep_ernie_1.0_large_ch/skep_ernie_1.0_large_ch.vocab.txt
[2021-06-25 16:19:54,007] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/skep_ernie_1.0_large_ch/skep_ernie_1.0_large_ch.pdparams
W0625 16:19:54.008798 3914 device_context.cc:362] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1
W0625 16:19:54.014358 3914 device_context.cc:372] device: 0, cuDNN Version: 7.6.
============start predict==========
Traceback (most recent call last):
File "sequence_labeling.py", line 335, in <module>
do_predict()
File "sequence_labeling.py", line 282, in do_predict
raise Exception("init checkpoints {} not exist".format(args.init_ckpt))
Exception: init checkpoints ./ckpt/DuEE1.0/trigger/best.pdparams not exist
end DuEE1.0 trigger predict
# 论元识别模型训练
!bash run_duee_1.sh role_train
check and create directory
dir ./ckpt exist
dir ./ckpt/DuEE1.0 exist
dir ./submit exist
start DuEE1.0 role train
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:26: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information.
Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
def convert_to_list(value, n, name, dtype=np.int):
[2021-06-25 16:29:56,644] [ INFO] - Found /home/aistudio/.paddlenlp/models/skep_ernie_1.0_large_ch/skep_ernie_1.0_large_ch.vocab.txt
[2021-06-25 16:29:56,654] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/skep_ernie_1.0_large_ch/skep_ernie_1.0_large_ch.pdparams
W0625 16:29:56.655723 5140 device_context.cc:362] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1
W0625 16:29:56.660176 5140 device_context.cc:372] device: 0, cuDNN Version: 7.6.
# 论元识别预测
!bash run_duee_1.sh role_predict
check and create directory
dir ./ckpt exist
dir ./ckpt/DuEE1.0 exist
dir ./submit exist
start DuEE1.0 role predict
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:26: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information.
Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
def convert_to_list(value, n, name, dtype=np.int):
[2021-06-25 16:20:51,515] [ INFO] - Found /home/aistudio/.paddlenlp/models/skep_ernie_1.0_large_ch/skep_ernie_1.0_large_ch.vocab.txt
[2021-06-25 16:20:51,525] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/skep_ernie_1.0_large_ch/skep_ernie_1.0_large_ch.pdparams
W0625 16:20:51.526757 4011 device_context.cc:362] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1
W0625 16:20:51.531198 4011 device_context.cc:372] device: 0, cuDNN Version: 7.6.
============start predict==========
Traceback (most recent call last):
File "sequence_labeling.py", line 335, in <module>
do_predict()
File "sequence_labeling.py", line 282, in do_predict
raise Exception("init checkpoints {} not exist".format(args.init_ckpt))
Exception: init checkpoints ./ckpt/DuEE1.0/role/best.pdparams not exist
end DuEE1.0 role predict
# 数据后处理,提交预测结果
# 结果存放于submit/test_duee_1.json
!bash run_duee_1.sh pred_2_submit
check and create directory
dir ./ckpt exist
dir ./ckpt/DuEE1.0 exist
dir ./submit exist
start DuEE1.0 predict data merge to submit fotmat
Traceback (most recent call last):
File "duee_1_postprocess.py", line 91, in <module>
args.save_path)
File "duee_1_postprocess.py", line 27, in predict_data_process
trigger_datas = read_by_lines(trigger_file)
File "/home/aistudio/event_extraction/utils.py", line 27, in read_by_lines
with open(path, "r") as infile:
FileNotFoundError: [Errno 2] No such file or directory: './ckpt/DuEE1.0/trigger/test_pred.json'
end DuEE1.0 role predict data merge
# import paddlenlp.transformers
# dir(paddlenlp.transformers)
评测方法
事件论元结果与人工标注的事件论元结果进行匹配,并按字级别匹配F1进行打分,不区分大小写,如论元有多个表述,则取多个匹配F1中的最高值
f1_score = (2 * P * R) / (P + R),其中
- P=预测论元得分总和 / 所有预测论元的数量
- R=预测论元得分总和 / 所有人工标注论元的数量
- 预测论元得分=事件类型是否准确 * 论元角色是否准确 * 字级别匹配F1值 (*是相乘)
- 字级别匹配F1值 = 2 * 字级别匹配P值 * 字级别匹配R值 / (字级别匹配P值 + 字级别匹配R值)
- 字级别匹配P值 = 预测论元和人工标注论元共有字的数量/ 预测论元字数
- 字级别匹配R值 = 预测论元和人工标注论元共有字的数量/ 人工标注论元字数
优化方法
尝试更多的预训练模型
基线采用的预训练模型为ERNIE,PaddleNLP提供了丰富的预训练模型,如BERT,RoBERTa,Electra,XLNet等。
如可以选择RoBERTa large中文模型优化模型效果,只需更换模型和tokenizer即可无缝衔接。
from paddlenlp.transformers import RobertaForTokenClassification, RobertaTokenizer
model = RobertaForTokenClassification.from_pretrained("roberta-wwm-ext-large", num_classes=len(label_map))
tokenizer = RobertaTokenizer.from_pretrained("roberta-wwm-ext-large")
修改模型网络结构
对于序列标注任务,大家会想到GRU+CRF作为常用网络,如何在预训练模型基础之上增加这些网络层呢?
import paddle.nn as nn
from paddlenlp.transformers import ErnieModel
from paddlenlp.layers import LinearChainCrf, LinearChainCrfLoss
class Model(ErnieModel):
def __init__(self, ernie, num_classes=2, dropout=None, gru_hidden_size=128):
super(Model, self).__init__()
self.num_classes = num_classes
# allow ernie to be config
self.ernie = ernie
self.dropout = nn.Dropout(dropout if dropout is not None else
self.ernie.config["hidden_dropout_prob"])
# add bi-gru
self.gru = nn.GRU(
input_size=self.ernie.config["hidden_size"],
hidden_size=gru_hidden_size,
direction='bidirect')
self.fc = nn.Linear(
in_features=gru_hidden_size * 2,
out_features=num_classes)
# add crf
self.crf = LinearChainCrf(
num_classes,
with_start_stop_tag=False)
self.crf_loss = LinearChainCrfLoss(self.crf)
self.viterbi_decoder = ViterbiDecoder(
self.crf.transitions,
with_start_stop_tag=False)
def forward(self,
input_ids,
token_type_ids=None,
position_ids=None,
attention_mask=None):
sequence_output, _ = self.ernie(
input_ids,
token_type_ids=token_type_ids,
position_ids=position_ids,
attention_mask=attention_mask)
sequence_output = self.dropout(sequence_output)
bigru_output, _ = self.gru(sequence_output)
emission = self.fc(bigru_output)
_, prediction = self.viterbi_decoder(emission, lengths)
if labels is not None:
loss = self.crf_loss(emission, lengths, prediction, labels)
return loss, lengths, prediction, labels
else:
return lengths, prediction
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:26: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information.
Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
def convert_to_list(value, n, name, dtype=np.int):
对于加了CRF层的模型,需要修改评价函数才能正常运行,修改代码如下:
@paddle.no_grad()
def evaluate(model, metric, data_loader):
model.eval()
metric.reset()
for input_ids, token_type_ids, seq_lens, labels in data_loader:
preds = model(input_ids, token_type_ids, seq_lens=seq_lens) #不传入label参数,就会返回预测结果标签
n_infer, n_label, n_correct = metric.compute(seq_lens, preds, labels)
metric.update(n_infer.numpy(), n_label.numpy(), n_correct.numpy())
precision, recall, f1_score = metric.accumulate()
print("eval precision: %f - recall: %f - f1: %f" %
(precision, recall, f1_score))
model.train()
return precision #返回精度作为评价指标
模型集成
使用多个模型进行训练预测,将各个模型预测结果进行融合。
以上基线实现基于PaddleNLP,开源不易,希望大家多多支持~ 记得给PaddleNLP点个小小的Star⭐
