基于深度学习的自然语言处理:PaddleNLP作业
https://exmachinelearning.github.io/PaddleNLP_Homework/
情感分析预训练模型SKEP比赛之——’ChnSentiCorp’,’NLPCC14-SC’,’SE-ABSA16_CAME’, ‘SE-ABSA16_PHNS’
本项目将详细全面介绍情感分析任务的两种子任务,句子级情感分析和目标级情感分析。
同时演示如何使用情感分析预训练模型SKEP完成以上两种任务,详细介绍预训练模型SKEP及其在 PaddleNLP 的使用方式。
本项目主要包括“任务介绍”、“情感分析预训练模型SKEP”、“句子级情感分析”、“目标级情感分析”等四个部分。
!pip install --upgrade paddlenlp -i https://pypi.org/simple
Collecting paddlenlp
[?25l Downloading https://files.pythonhosted.org/packages/b1/e9/128dfc1371db3fc2fa883d8ef27ab6b21e3876e76750a43f58cf3c24e707/paddlenlp-2.0.2-py3-none-any.whl (426kB)
[K |████████████████████████████████| 430kB 350kB/s eta 0:00:01
[?25hRequirement already satisfied, skipping upgrade: multiprocess in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp) (0.70.11.1)
Requirement already satisfied, skipping upgrade: h5py in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp) (2.9.0)
Requirement already satisfied, skipping upgrade: jieba in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp) (0.42.1)
Requirement already satisfied, skipping upgrade: visualdl in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp) (2.1.1)
Requirement already satisfied, skipping upgrade: colorlog in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp) (4.1.0)
Requirement already satisfied, skipping upgrade: seqeval in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp) (1.2.2)
Requirement already satisfied, skipping upgrade: colorama in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp) (0.4.4)
Requirement already satisfied, skipping upgrade: dill>=0.3.3 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from multiprocess->paddlenlp) (0.3.3)
Requirement already satisfied, skipping upgrade: six in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from h5py->paddlenlp) (1.15.0)
Requirement already satisfied, skipping upgrade: numpy>=1.7 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from h5py->paddlenlp) (1.20.3)
Requirement already satisfied, skipping upgrade: pre-commit in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl->paddlenlp) (1.21.0)
Requirement already satisfied, skipping upgrade: Flask-Babel>=1.0.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl->paddlenlp) (1.0.0)
Requirement already satisfied, skipping upgrade: Pillow>=7.0.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl->paddlenlp) (7.1.2)
Requirement already satisfied, skipping upgrade: bce-python-sdk in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl->paddlenlp) (0.8.53)
Requirement already satisfied, skipping upgrade: requests in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl->paddlenlp) (2.22.0)
Requirement already satisfied, skipping upgrade: shellcheck-py in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl->paddlenlp) (0.7.1.1)
Requirement already satisfied, skipping upgrade: flask>=1.1.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl->paddlenlp) (1.1.1)
Requirement already satisfied, skipping upgrade: flake8>=3.7.9 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl->paddlenlp) (3.8.2)
Requirement already satisfied, skipping upgrade: protobuf>=3.11.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl->paddlenlp) (3.14.0)
Requirement already satisfied, skipping upgrade: scikit-learn>=0.21.3 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from seqeval->paddlenlp) (0.24.2)
Requirement already satisfied, skipping upgrade: virtualenv>=15.2 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pre-commit->visualdl->paddlenlp) (16.7.9)
Requirement already satisfied, skipping upgrade: cfgv>=2.0.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pre-commit->visualdl->paddlenlp) (2.0.1)
Requirement already satisfied, skipping upgrade: nodeenv>=0.11.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pre-commit->visualdl->paddlenlp) (1.3.4)
Requirement already satisfied, skipping upgrade: aspy.yaml in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pre-commit->visualdl->paddlenlp) (1.3.0)
Requirement already satisfied, skipping upgrade: importlib-metadata; python_version < "3.8" in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pre-commit->visualdl->paddlenlp) (0.23)
Requirement already satisfied, skipping upgrade: identify>=1.0.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pre-commit->visualdl->paddlenlp) (1.4.10)
Requirement already satisfied, skipping upgrade: pyyaml in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pre-commit->visualdl->paddlenlp) (5.1.2)
Requirement already satisfied, skipping upgrade: toml in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pre-commit->visualdl->paddlenlp) (0.10.0)
Requirement already satisfied, skipping upgrade: pytz in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from Flask-Babel>=1.0.0->visualdl->paddlenlp) (2019.3)
Requirement already satisfied, skipping upgrade: Babel>=2.3 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from Flask-Babel>=1.0.0->visualdl->paddlenlp) (2.8.0)
Requirement already satisfied, skipping upgrade: Jinja2>=2.5 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from Flask-Babel>=1.0.0->visualdl->paddlenlp) (2.10.1)
Requirement already satisfied, skipping upgrade: future>=0.6.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from bce-python-sdk->visualdl->paddlenlp) (0.18.0)
Requirement already satisfied, skipping upgrade: pycryptodome>=3.8.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from bce-python-sdk->visualdl->paddlenlp) (3.9.9)
Requirement already satisfied, skipping upgrade: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from requests->visualdl->paddlenlp) (1.25.6)
Requirement already satisfied, skipping upgrade: idna<2.9,>=2.5 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from requests->visualdl->paddlenlp) (2.8)
Requirement already satisfied, skipping upgrade: certifi>=2017.4.17 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from requests->visualdl->paddlenlp) (2019.9.11)
Requirement already satisfied, skipping upgrade: chardet<3.1.0,>=3.0.2 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from requests->visualdl->paddlenlp) (3.0.4)
Requirement already satisfied, skipping upgrade: click>=5.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from flask>=1.1.1->visualdl->paddlenlp) (7.0)
Requirement already satisfied, skipping upgrade: itsdangerous>=0.24 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from flask>=1.1.1->visualdl->paddlenlp) (1.1.0)
Requirement already satisfied, skipping upgrade: Werkzeug>=0.15 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from flask>=1.1.1->visualdl->paddlenlp) (0.16.0)
Requirement already satisfied, skipping upgrade: pycodestyle<2.7.0,>=2.6.0a1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from flake8>=3.7.9->visualdl->paddlenlp) (2.6.0)
Requirement already satisfied, skipping upgrade: mccabe<0.7.0,>=0.6.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from flake8>=3.7.9->visualdl->paddlenlp) (0.6.1)
Requirement already satisfied, skipping upgrade: pyflakes<2.3.0,>=2.2.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from flake8>=3.7.9->visualdl->paddlenlp) (2.2.0)
Requirement already satisfied, skipping upgrade: scipy>=0.19.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from scikit-learn>=0.21.3->seqeval->paddlenlp) (1.6.3)
Requirement already satisfied, skipping upgrade: joblib>=0.11 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from scikit-learn>=0.21.3->seqeval->paddlenlp) (0.14.1)
Requirement already satisfied, skipping upgrade: threadpoolctl>=2.0.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from scikit-learn>=0.21.3->seqeval->paddlenlp) (2.1.0)
Requirement already satisfied, skipping upgrade: zipp>=0.5 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from importlib-metadata; python_version < "3.8"->pre-commit->visualdl->paddlenlp) (0.6.0)
Requirement already satisfied, skipping upgrade: MarkupSafe>=0.23 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from Jinja2>=2.5->Flask-Babel>=1.0.0->visualdl->paddlenlp) (1.1.1)
Requirement already satisfied, skipping upgrade: more-itertools in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from zipp>=0.5->importlib-metadata; python_version < "3.8"->pre-commit->visualdl->paddlenlp) (7.2.0)
Installing collected packages: paddlenlp
Found existing installation: paddlenlp 2.0.1
Uninstalling paddlenlp-2.0.1:
Successfully uninstalled paddlenlp-2.0.1
Successfully installed paddlenlp-2.0.2
Part A. 情感分析任务
众所周知,人类自然语言中包含了丰富的情感色彩:表达人的情绪(如悲伤、快乐)、表达人的心情(如倦怠、忧郁)、表达人的喜好(如喜欢、讨厌)、表达人的个性特征和表达人的立场等等。情感分析在商品喜好、消费决策、舆情分析等场景中均有应用。利用机器自动分析这些情感倾向,不但有助于帮助企业了解消费者对其产品的感受,为产品改进提供依据;同时还有助于企业分析商业伙伴们的态度,以便更好地进行商业决策。
被人们所熟知的情感分析任务是将一段文本分类,如分为情感极性为正向、负向、其他的三分类问题:
</br>

- 正向: 表示正面积极的情感,如高兴,幸福,惊喜,期待等。
- 负向: 表示负面消极的情感,如难过,伤心,愤怒,惊恐等。
- 其他: 其他类型的情感。
实际上,以上熟悉的情感分析任务是句子级情感分析任务。
情感分析任务还可以进一步分为句子级情感分析、目标级情感分析等任务。在下面章节将会详细介绍两种任务及其应用场景。
Part B. 情感分析预训练模型SKEP
近年来,大量的研究表明基于大型语料库的预训练模型(Pretrained Models, PTM)可以学习通用的语言表示,有利于下游NLP任务,同时能够避免从零开始训练模型。随着计算能力的发展,深度模型的出现(即 Transformer)和训练技巧的增强使得 PTM 不断发展,由浅变深。
情感预训练模型SKEP(Sentiment Knowledge Enhanced Pre-training for Sentiment Analysis)。SKEP利用情感知识增强预训练模型, 在14项中英情感分析典型任务上全面超越SOTA,此工作已经被ACL 2020录用。SKEP是百度研究团队提出的基于情感知识增强的情感预训练算法,此算法采用无监督方法自动挖掘情感知识,然后利用情感知识构建预训练目标,从而让机器学会理解情感语义。SKEP为各类情感分析任务提供统一且强大的情感语义表示。
论文地址:https://arxiv.org/abs/2005.05635
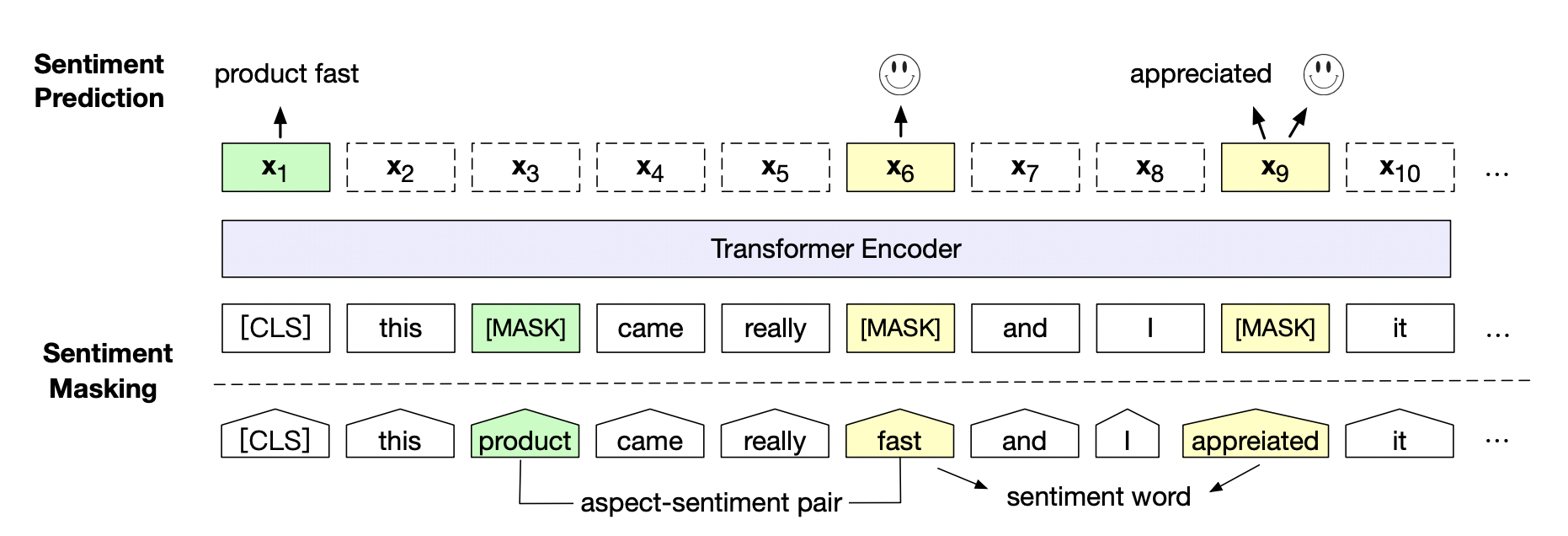
百度研究团队在三个典型情感分析任务,句子级情感分类(Sentence-level Sentiment Classification),评价目标级情感分类(Aspect-level Sentiment Classification)、观点抽取(Opinion Role Labeling),共计14个中英文数据上进一步验证了情感预训练模型SKEP的效果。
具体实验效果参考:https://github.com/baidu/Senta#skep
Part C 句子级情感分析 & 目标级情感分析
Part C.1 句子级情感分析
对给定的一段文本进行情感极性分类,常用于影评分析、网络论坛舆情分析等场景。如:
选择珠江花园的原因就是方便,有电动扶梯直接到达海边,周围餐馆、食廊、商场、超市、摊位一应俱全。酒店装修一般,但还算整洁。 泳池在大堂的屋顶,因此很小,不过女儿倒是喜欢。 包的早餐是西式的,还算丰富。 服务吗,一般 1
15.4寸笔记本的键盘确实爽,基本跟台式机差不多了,蛮喜欢数字小键盘,输数字特方便,样子也很美观,做工也相当不错 1
房间太小。其他的都一般。。。。。。。。。 0
其中1表示正向情感,0表示负向情感。
</br>
常用数据集
ChnSenticorp数据集是公开中文情感分析常用数据集, 其为2分类数据集。PaddleNLP已经内置该数据集,一键即可加载。
user_dir = '/home/aistudio/'
traindataset = 'SE-ABSA16_CAME' #选择进行训练的数据集['ChnSentiCorp','NLPCC14-SC','SE-ABSA16_CAME', 'SE-ABSA16_PHNS', 'COTE_BD', 'COTE_MFW', 'COTE_DP']
import os
import random
# 读取tsv
def read_tsv(tsv):
datas = []
headline = None
with open(tsv, 'r', encoding='UTF-8') as f:
for i, line in enumerate(f):
if i==0:
print(line)
headline = line
continue
else:
data = line.strip('\n\t').split('\t')
datas.append('\t'.join(data)+'\n')
return datas,headline
# 写入tsv
def write_tsv(tsv, datas):
with open(tsv, 'w', encoding='UTF-8') as f:
for line in datas:
f.write(line)
# 切分并转换
def split_dataset_change(tsv, split_pro):
random.seed(10)
datas,headline = read_tsv(tsv)
random.shuffle(datas)
# print(datas[:5])
split_num = int(split_pro*len(datas))
trainlist = datas[:split_num]
trainlist.insert(0,headline)
write_tsv(tsv, trainlist) #save train.tsv
devlist = datas[split_num:]
devlist.insert(0,headline)
write_tsv('/'.join(tsv.split('/')[:-1])+'/dev.tsv', devlist) #save dev.tsv
1.1 ChnSentiCorp数据集
from paddlenlp.datasets import load_dataset
train_ds, dev_ds, test_ds = load_dataset("chnsenticorp", splits=["train", "dev", "test"])
print('-'*5+'train sample data'+'-'*5)
print(train_ds[0])
print(train_ds[1])
print(train_ds[2])
print('-'*5+'dev sample data'+'-'*5)
print(dev_ds[0])
print(dev_ds[1])
print(dev_ds[2])
print('-'*5+'test sample data'+'-'*5)
print(test_ds[0])
print(test_ds[1])
print(test_ds[2])
-----train sample data-----
{'text': '选择珠江花园的原因就是方便,有电动扶梯直接到达海边,周围餐馆、食廊、商场、超市、摊位一应俱全。酒店装修一般,但还算整洁。 泳池在大堂的屋顶,因此很小,不过女儿倒是喜欢。 包的早餐是西式的,还算丰富。 服务吗,一般', 'label': 1, 'qid': ''}
{'text': '15.4寸笔记本的键盘确实爽,基本跟台式机差不多了,蛮喜欢数字小键盘,输数字特方便,样子也很美观,做工也相当不错', 'label': 1, 'qid': ''}
{'text': '房间太小。其他的都一般。。。。。。。。。', 'label': 0, 'qid': ''}
-----dev sample data-----
{'text': '這間酒店環境和服務態度亦算不錯,但房間空間太小~~不宣容納太大件行李~~且房間格調還可以~~ 中餐廳的廣東點心不太好吃~~要改善之~~~~但算價錢平宜~~可接受~~ 西餐廳格調都很好~~但吃的味道一般且令人等得太耐了~~要改善之~~', 'label': 1, 'qid': '0'}
{'text': '<荐书> 推荐所有喜欢<红楼>的红迷们一定要收藏这本书,要知道当年我听说这本书的时候花很长时间去图书馆找和借都没能如愿,所以这次一看到当当有,马上买了,红迷们也要记得备货哦!', 'label': 1, 'qid': '1'}
{'text': '商品的不足暂时还没发现,京东的订单处理速度实在.......周二就打包完成,周五才发货...', 'label': 0, 'qid': '2'}
-----test sample data-----
{'text': '这个宾馆比较陈旧了,特价的房间也很一般。总体来说一般', 'label': '', 'qid': '0'}
{'text': '怀着十分激动的心情放映,可是看着看着发现,在放映完毕后,出现一集米老鼠的动画片!开始还怀疑是不是赠送的个别现象,可是后来发现每张DVD后面都有!真不知道生产商怎么想的,我想看的是猫和老鼠,不是米老鼠!如果厂家是想赠送的话,那就全套米老鼠和唐老鸭都赠送,只在每张DVD后面添加一集算什么??简直是画蛇添足!!', 'label': '', 'qid': '1'}
{'text': '还稍微重了点,可能是硬盘大的原故,还要再轻半斤就好了。其他要进一步验证。贴的几种膜气泡较多,用不了多久就要更换了,屏幕膜稍好点,但比没有要强多了。建议配赠几张膜让用用户自己贴。', 'label': '', 'qid': '2'}
1.2 NLPCC14-SC 数据集
!unzip ./data/data53469/NLPCC14-SC.zip -d ~/data/
!rm -r ./data/__MACOSX/
Archive: ./data/data53469/NLPCC14-SC.zip
inflating: /home/aistudio/data/NLPCC14-SC/License.pdf
inflating: /home/aistudio/data/NLPCC14-SC/test.tsv
inflating: /home/aistudio/data/NLPCC14-SC/train.tsv
rm: cannot remove './data/__MACOSX/': No such file or directory
split_dataset_change(os.path.join(user_dir,'data',traindataset,'train.tsv'), 0.8) #该数据集只有train和test,需要手动将train拆分为train和dev
from paddlenlp.datasets import DatasetBuilder
import os
class NLPCC14_SC(DatasetBuilder):
SPLITS = {
'train': os.path.join(user_dir,'data','NLPCC14-SC','train.tsv'),
'dev': os.path.join(user_dir,'data','NLPCC14-SC','dev.tsv'),
'test': os.path.join(user_dir,'data','NLPCC14-SC','test.tsv'),
}
def _get_data(self, mode, **kwargs):
filename = self.SPLITS[mode]
return filename
def _read(self, filename, split):
with open(filename, 'r', encoding='utf-8') as f:
head = None
for line in f:
data = line.strip().split("\t")
if not head:
head = data
else:
if split == 'train' or split == 'dev':
label, text = data
yield {"text": text, "label": label, "qid": ''}
elif split == 'test':
qid, text = data
yield {"text": text, "label": '', "qid": qid}
def get_labels(self):
return ["0", "1"]
if traindataset == 'NLPCC14-SC':
print('construct NLPCC14-SC')
def load_dataset(name=None,
data_files=None,
splits=None,
lazy=None,
**kwargs):
reader_cls = NLPCC14_SC
print(reader_cls)
if not name:
reader_instance = reader_cls(lazy=lazy, **kwargs)
else:
reader_instance = reader_cls(lazy=lazy, name=name, **kwargs)
datasets = reader_instance.read_datasets(data_files=data_files, splits=splits)
return datasets
# 一键加载 bq_corpus 的训练集、验证集
train_ds, dev_ds, test_ds = load_dataset("chnsenticorp", splits=["train", "dev", "test"])
# 输出测试样本
print('-'*5+'train sample data'+'-'*5)
print(train_ds[0])
print(train_ds[1])
print(train_ds[2])
print('-'*5+'dev sample data'+'-'*5)
print(dev_ds[0])
print(dev_ds[1])
print(dev_ds[2])
print('-'*5+'test sample data'+'-'*5)
print(test_ds[0])
print(test_ds[1])
print(test_ds[2])
construct NLPCC14-SC
<class '__main__.NLPCC14_SC'>
-----train sample data-----
{'text': '这个不错', 'label': 1, 'qid': ''}
{'text': '这都半个月了,才发货还只是发了一部分你们的服务还能再慢点不?', 'label': 0, 'qid': ''}
{'text': '一直在等这张 终于可以购买了 歌曲全部都能唱了 呵呵', 'label': 1, 'qid': ''}
-----dev sample data-----
{'text': '好听,还是好听', 'label': 0, 'qid': ''}
{'text': '比较划算,虽然只装了两台电脑,偶尔感觉会占内存,其他的还不错', 'label': 1, 'qid': ''}
{'text': '这套碟怎么没有赠盘的,打客服电话也打不通,真是麻烦死了,29张碟的质量也有点小问题,不过勉强可以使用', 'label': 0, 'qid': ''}
-----test sample data-----
{'text': '我终于找到同道中人啦~~~~从初中开始,我就已经喜欢上了michaeljackson.但同学们都用鄙夷的眼光看我,他们人为jackson的样子古怪甚至说"丑".我当场气晕.但现在有同道中人了,我好开心!!!michaeljacksonisthemostsuccessfulsingerintheworld!!~~~', 'label': '', 'qid': '0'}
{'text': '看完已是深夜两点,我却坐在电脑前情难自禁,这是最好的结局。惟有如此,就让那前世今生的纠结就停留在此刻。再相逢时,愿他的人生不再让人唏嘘,他们的身心也会只居一处。可是还是痛心为这样的人,这样的爱……', 'label': '', 'qid': '1'}
{'text': '袁阔成先生是当今评书界的泰斗,十二金钱镖是他的代表作之一', 'label': '', 'qid': '2'}
1.3 SE-ABSA16_CAME数据集
!unzip ./data/data53469/SE-ABSA16_CAME.zip -d ~/data/
!rm -r ./data/__MACOSX/
Archive: ./data/data53469/SE-ABSA16_CAME.zip
replace /home/aistudio/data/SE-ABSA16_CAME/License.pdf? [y]es, [n]o, [A]ll, [N]one, [r]ename: ^C
rm: cannot remove './data/__MACOSX/': No such file or directory
split_dataset_change(os.path.join(user_dir,'data',traindataset,'train.tsv'), 0.8) #该数据集只有train和test,需要手动将train拆分为train和dev
label text_a text_b
from paddlenlp.datasets import DatasetBuilder
import os
class SE_ABSA16_CAME(DatasetBuilder):
SPLITS = {
'train': [os.path.join(user_dir,'data',traindataset,'train.tsv'),(0, 1, 2), 1],
'dev': [os.path.join(user_dir,'data',traindataset,'dev.tsv'),(0, 1, 2), 1],
'test': [os.path.join(user_dir,'data',traindataset,'test.tsv'), (1, 2), 1],
}
def _get_data(self, mode, **kwargs):
filename,_,_ = self.SPLITS[mode]
return filename
def _read(self, filename, split):
_, field_indices, num_discard_samples = self.SPLITS[split]
with open(filename, 'r', encoding='utf-8') as f:
for idx, line in enumerate(f):
if idx < num_discard_samples:
continue
line_stripped = line.strip().split('\t')
if not line_stripped:
continue
example = [line_stripped[indice] for indice in field_indices]
if split == 'test':
yield {"text": example[0], "text_pair": example[1]}
else:
yield {
"text": example[1],
"text_pair": example[2],
"label": example[0]
}
def get_labels(self):
return ["0", "1"]
if traindataset == 'SE-ABSA16_CAME':
print('construct SE-ABSA16_CAME')
def load_dataset(name=None,
data_files=None,
splits=None,
lazy=None,
**kwargs):
reader_cls = SE_ABSA16_CAME
print(reader_cls)
if not name:
reader_instance = reader_cls(lazy=lazy, **kwargs)
else:
reader_instance = reader_cls(lazy=lazy, name=name, **kwargs)
datasets = reader_instance.read_datasets(data_files=data_files, splits=splits)
return datasets
# 一键加载 bq_corpus 的训练集、验证集
train_ds, dev_ds, test_ds = load_dataset(traindataset, splits=["train", "dev", "test"])
# train_ds, test_ds = load_dataset(traindataset, splits=["train", "test"])
# 输出测试样本
print('-'*5+'train sample data'+'-'*5)
print(train_ds[0])
print(train_ds[1])
print(train_ds[2])
# print('-'*5+'dev sample data'+'-'*5)
# print(dev_ds[0])
# print(dev_ds[1])
# print(dev_ds[2])
print('-'*5+'test sample data'+'-'*5)
print(test_ds[0])
print(test_ds[1])
print(test_ds[2])
construct SE-ABSA16_CAME
<class '__main__.SE_ABSA16_CAME'>
-----train sample data-----
{'text': 'ports#connectivity', 'text_pair': 'NEX-6在NEX-5n优秀的画质之上,增加了相位对焦、取景器、闪光灯接口,增加了相位对焦、取景器、闪光灯接口,增加了相位对焦、取景器、闪光灯接口,增强了手感。除了没有触摸屏以外,基本上NEX-5n缺的,它都补上了,是性能优秀,性价比上佳的机器,也是我个人意见中,第一台能真正替代单反的无反相机。对焦比较快速、准确;握在手里比尼康D7000手感要好。主要问题:这机子分大陆版和世界各地版。其他市场上的NEX-6都是带APP功能的,可以在相机上安装网上的各种小插件,包括定时快门、机内PS、远程操作等。国行的NEX-6既没有APP功能,视频最高帧率又只有50P(根据国内视频制式不同,SONY的相机分50P和60P版),配置是世界上最低的,所以价格也比水货便宜将近1000人民币,购买前应注意区别。', 'label': 0}
{'text': 'hardware#usability', 'text_pair': '入手便携机G15,谈初步感受昨天入手,3650未税。想了很久,毕竟这个价格超过一台入门单反了。值吗?可是想一部便携机也很久了,不想再等了。那一天快到了,谁知道会咋样呢。谈谈初步的感受,给同好做个参考吧。1.体积,买前和G12比较了一下,薄了,小了一些,还是能明显的看出来的。买回来后感觉再小点就更好了,可是看镜头和光学取景器的位置似乎也不能再小了。2.光学取景器,有人说没必要,有人说能看到镜头。其实用过此类机子的都应该知道,广角时挡一点没什么大不了的,除了心情也不影响什么。至于有没有必要,这个我就不说了,个人习惯吧,青菜萝卜的事咋能说清呢。3.镜头,28-140 1.8-2.8 玩过单反的都知道这样的焦距,光圈意味着什么。太方便了。4.曝光,感觉强的不是一点点,很暗的地方都能轻松拍出来。曝光补偿单独拨轮很实用。5.白平衡,灯光下不准。这是我没想到的,感觉是算法的原因。佳能旗舰DC,竟然在这个上面出问题。。。6.ISO,默认是AUTO,用了挺方便,但是搞不清最小快门是怎么控制的。经常是1/20秒。尼康的都好设置的。佳能5D3才有这个功能。这个不好。7.纸质说明书,数据线都不配,太省钱了,还说是为环保。。。8.热靴,可以用永诺460,当然是手动的;也可以用引闪器离机引闪,很好。9.总而言之是一部很好用的随身机子,菜单里东西蛮多,还在熟悉中。', 'label': 1}
{'text': 'focus#operation_performance', 'text_pair': 'NEX-5n小巧的高画质尼康D7000微缩版,价格一半以下。画质优秀,对焦尚可,手感不错,最便宜的1080 50/60P摄像机。固件升级后的机器可以设置自定义键,操作更加便捷。感光度、白平衡、测光、对焦模式、画质、连拍速度等常用设置都可以在2步操作以内进行调整。主要的问题:1、 只有一个外置接口。因为习惯了单反,我的NEX-5n总是接着外置的电子取景器。但问题是闪光灯也得用同一个外置接口,于是常常得在取景器和闪光灯之间换来换去,很不方便。2、 触摸屏。用过m4/3系统的人绝对会受不了索尼NEX的触摸屏,因为实在差太远了。松下的GH2的触摸屏灵敏、快速,单单一个“爽”字哪能形容。我曾一度习惯了把相机捧在腰间,左手大姆指点屏幕对焦,右手大姆指按快门的拍摄方法。相比之下,目前的NEX触摸屏除了用于菜单以外,基本没用。', 'label': 1}
-----test sample data-----
{'text': 'camera#quality', 'text_pair': '一直潜水,昨天入d300s +35 1.8g,谈谈感受,dx说,标题一定要长!在我们这尼康一个代理商开的大型体验中心提的货,老板和销售mm都很热情,不欺诈,也没有店大欺客,mm很热情,从d300s到d800,d7000,到d3x配各种镜头,全部把玩了一番,感叹啊,真他妈好东西!尤其d3x,有钱了,一定要他妈买一个,还有,就是d800,一摸心中的神机,顿时凉了半截,可能摸她之前,摸了她们的头牌,d3x的缘故,这手感 真是差了点,样子嘛,之所以喜欢尼康,就是喜欢棱角分明的感觉,d3x方方正正 ,甚是讨喜,d800这丫头,变得圆滑了不少,不喜欢。都说电子产品,买新不买旧,我倒不认为这么看,中低端产品的确如此,但顶级的高端产品,真不是这么回事啊,d3x也是51点对焦,我的d300s也是51点,但明显感觉,对焦就是比d300s 快,准,暗部反差较小时,也很少拉风箱,我的d300s就不行,光线不好反差较小,拉回来拉过去,半天合不上焦,说真的,一分价钱一分货啊,d800电子性能 肯定是先进的,但机械性能 跟d3x还是没可比性,传感器固然先进,但三千多万 像素 和两千多万像素 对我们来说,真的差别这么大吗?d800e3万多,有这钱真的不如加点买 d3x啊,真要是d3x烂,为什么尼康不停产了?人说高像素 是给商业摄影师用,我们的音乐老师,是业余的音乐制作人,也拍摄一些商业广告,平时他玩的时候 都是数码什么的,nc 加起来十几个,大三元全都配齐,但干活的时候,还是120的机器,照他那话说,数码 像素太低,不够用啊!废话说太多了,谈谈感受吧,当初一直在纠结d7000和d300s,都说什么d7000画质超越d300s,我也信,但昨天拿到实机后,我瞬间就决定 d300s了,我的手算小的,握住d300s,我感觉,刚刚好,而且手柄凹槽 ,我觉得还不够深,握感不是十分的充盈,这点要像宾得k5学习,而且d7000小了一点,背部操作空间局促,大拇指没地放,果断d300s,而且试机的时候,我给d300s 换上了24-70,可能我练健身比较久了,没感觉有啥重量,蛮趁手的,现在配35 1.8 感觉轻飘飘的,哈哈,'}
{'text': 'focus#operation_performance', 'text_pair': '一直潜水,昨天入d300s +35 1.8g,谈谈感受,dx说,标题一定要长!在我们这尼康一个代理商开的大型体验中心提的货,老板和销售mm都很热情,不欺诈,也没有店大欺客,mm很热情,从d300s到d800,d7000,到d3x配各种镜头,全部把玩了一番,感叹啊,真他妈好东西!尤其d3x,有钱了,一定要他妈买一个,还有,就是d800,一摸心中的神机,顿时凉了半截,可能摸她之前,摸了她们的头牌,d3x的缘故,这手感 真是差了点,样子嘛,之所以喜欢尼康,就是喜欢棱角分明的感觉,d3x方方正正 ,甚是讨喜,d800这丫头,变得圆滑了不少,不喜欢。都说电子产品,买新不买旧,我倒不认为这么看,中低端产品的确如此,但顶级的高端产品,真不是这么回事啊,d3x也是51点对焦,我的d300s也是51点,但明显感觉,对焦就是比d300s 快,准,暗部反差较小时,也很少拉风箱,我的d300s就不行,光线不好反差较小,拉回来拉过去,半天合不上焦,说真的,一分价钱一分货啊,d800电子性能 肯定是先进的,但机械性能 跟d3x还是没可比性,传感器固然先进,但三千多万 像素 和两千多万像素 对我们来说,真的差别这么大吗?d800e3万多,有这钱真的不如加点买 d3x啊,真要是d3x烂,为什么尼康不停产了?人说高像素 是给商业摄影师用,我们的音乐老师,是业余的音乐制作人,也拍摄一些商业广告,平时他玩的时候 都是数码什么的,nc 加起来十几个,大三元全都配齐,但干活的时候,还是120的机器,照他那话说,数码 像素太低,不够用啊!废话说太多了,谈谈感受吧,当初一直在纠结d7000和d300s,都说什么d7000画质超越d300s,我也信,但昨天拿到实机后,我瞬间就决定 d300s了,我的手算小的,握住d300s,我感觉,刚刚好,而且手柄凹槽 ,我觉得还不够深,握感不是十分的充盈,这点要像宾得k5学习,而且d7000小了一点,背部操作空间局促,大拇指没地放,果断d300s,而且试机的时候,我给d300s 换上了24-70,可能我练健身比较久了,没感觉有啥重量,蛮趁手的,现在配35 1.8 感觉轻飘飘的,哈哈,'}
{'text': 'camera#quality', 'text_pair': '一直潜水,昨天入d300s +35 1.8g,谈谈感受,dx说,标题一定要长!在我们这尼康一个代理商开的大型体验中心提的货,老板和销售mm都很热情,不欺诈,也没有店大欺客,mm很热情,从d300s到d800,d7000,到d3x配各种镜头,全部把玩了一番,感叹啊,真他妈好东西!尤其d3x,有钱了,一定要他妈买一个,还有,就是d800,一摸心中的神机,顿时凉了半截,可能摸她之前,摸了她们的头牌,d3x的缘故,这手感 真是差了点,样子嘛,之所以喜欢尼康,就是喜欢棱角分明的感觉,d3x方方正正 ,甚是讨喜,d800这丫头,变得圆滑了不少,不喜欢。都说电子产品,买新不买旧,我倒不认为这么看,中低端产品的确如此,但顶级的高端产品,真不是这么回事啊,d3x也是51点对焦,我的d300s也是51点,但明显感觉,对焦就是比d300s 快,准,暗部反差较小时,也很少拉风箱,我的d300s就不行,光线不好反差较小,拉回来拉过去,半天合不上焦,说真的,一分价钱一分货啊,d800电子性能 肯定是先进的,但机械性能 跟d3x还是没可比性,传感器固然先进,但三千多万 像素 和两千多万像素 对我们来说,真的差别这么大吗?d800e3万多,有这钱真的不如加点买 d3x啊,真要是d3x烂,为什么尼康不停产了?人说高像素 是给商业摄影师用,我们的音乐老师,是业余的音乐制作人,也拍摄一些商业广告,平时他玩的时候 都是数码什么的,nc 加起来十几个,大三元全都配齐,但干活的时候,还是120的机器,照他那话说,数码 像素太低,不够用啊!废话说太多了,谈谈感受吧,当初一直在纠结d7000和d300s,都说什么d7000画质超越d300s,我也信,但昨天拿到实机后,我瞬间就决定 d300s了,我的手算小的,握住d300s,我感觉,刚刚好,而且手柄凹槽 ,我觉得还不够深,握感不是十分的充盈,这点要像宾得k5学习,而且d7000小了一点,背部操作空间局促,大拇指没地放,果断d300s,而且试机的时候,我给d300s 换上了24-70,可能我练健身比较久了,没感觉有啥重量,蛮趁手的,现在配35 1.8 感觉轻飘飘的,哈哈,'}
1.4 SE-ABSA16_PHNS数据集
!unzip ./data/data53469/SE-ABSA16_PHNS.zip -d ~/data/
!rm -r ./data/__MACOSX/
Archive: ./data/data53469/SE-ABSA16_PHNS.zip
inflating: /home/aistudio/data/SE-ABSA16_PHNS/License.pdf
inflating: /home/aistudio/data/SE-ABSA16_PHNS/test.tsv
inflating: /home/aistudio/data/SE-ABSA16_PHNS/train.tsv
rm: cannot remove './data/__MACOSX/': No such file or directory
split_dataset_change(os.path.join(user_dir,'data',traindataset,'train.tsv'), 0.8) #该数据集只有train和test,需要手动将train拆分为train和dev
label text_a text_b
from paddlenlp.datasets import DatasetBuilder
import os
class SE_ABSA16_PHNS(DatasetBuilder):
SPLITS = {
'train': [os.path.join(user_dir,'data',traindataset,'train.tsv'),(0, 1, 2), 1],
'dev': [os.path.join(user_dir,'data',traindataset,'dev.tsv'),(0, 1, 2), 1],
'test': [os.path.join(user_dir,'data',traindataset,'test.tsv'), (1, 2), 1],
}
def _get_data(self, mode, **kwargs):
filename,_,_ = self.SPLITS[mode]
return filename
def _read(self, filename, split):
_, field_indices, num_discard_samples = self.SPLITS[split]
with open(filename, 'r', encoding='utf-8') as f:
for idx, line in enumerate(f):
if idx < num_discard_samples:
continue
line_stripped = line.strip().split('\t')
if not line_stripped:
continue
example = [line_stripped[indice] for indice in field_indices]
if split == 'test':
yield {"text": example[0], "text_pair": example[1]}
else:
yield {
"text": example[1],
"text_pair": example[2],
"label": example[0]
}
def get_labels(self):
return ["0", "1"]
if traindataset == 'SE-ABSA16_PHNS':
print('construct SE-ABSA16_PHNS')
def load_dataset(name=None,
data_files=None,
splits=None,
lazy=None,
**kwargs):
reader_cls = SE_ABSA16_PHNS
print(reader_cls)
if not name:
reader_instance = reader_cls(lazy=lazy, **kwargs)
else:
reader_instance = reader_cls(lazy=lazy, name=name, **kwargs)
datasets = reader_instance.read_datasets(data_files=data_files, splits=splits)
return datasets
# 一键加载 bq_corpus 的训练集、验证集
train_ds, dev_ds, test_ds = load_dataset(traindataset, splits=["train", "dev", "test"])
# 输出测试样本
print('-'*5+'train sample data'+'-'*5)
print(train_ds[0])
print(train_ds[1])
print(train_ds[2])
print('-'*5+'dev sample data'+'-'*5)
print(dev_ds[0])
print(dev_ds[1])
print(dev_ds[2])
print('-'*5+'test sample data'+'-'*5)
print(test_ds[0])
print(test_ds[1])
print(test_ds[2])
construct SE-ABSA16_PHNS
<class '__main__.SE_ABSA16_PHNS'>
-----train sample data-----
{'text': 'support#quality', 'text_pair': '华为W1体验提醒购买手机的朋友,手机主要存在以下问题:向上滑动时,字迹模糊,是比较厉害的那种,眼睛会感到有点晕;其次,刚取回体验竟然不能拨打电话:点拨号键,不出键盘,20秒左右自动返回主菜单;后来点通话记录,竟然挂不掉电话,后来干脆卡死,无法关机,只能扣电池。之前一直用诺基亚,这次想体验国产没想到付出了惨重代价,然后我评价后,竟然华为商品评价里面没有我的评价,哎,何止是对手机产品失望啊?服务也不满意,因为手机关系到转寄,提前几天都给客服人员说让安排转寄,但是6天了没有效果,只能自己花半天时间取货,华为说的最多的就是尽快解决,但是没有效果,手机我也不敢退货了,怕再被黑了。不过手机确实蛮好看的,可是拍照质量不怎样,音质一般,打电话扬声器有回音还变音,还有尖叫的噪音,可能是距离近了,这个还待观察,还有其他问题以后持续追0踪。', 'label': 0}
{'text': 'phone#design_features', 'text_pair': '关于用SONY lt22i之感受 提供优点缺点一,优点1.手机造型美观,手机造型个人认为不错,我不喜欢HTC的那种风格的工艺造型,LG本人也最为认可P970的设计,苹果都是一个样就提了,sony这款拿在手里,感觉很优雅吧,会觉得手机偏长,但是造型算是很不错的,透明带的确加分,很美观。铝合金的材质很加分。2.充电快,这款手机电池虽然容量并不是太高 1300MA,但是充电很快的,两个小时大概就可以充满,而且在听筒旁边有个指示灯,充电的过程,会由橙变绿。本人使用早上七点出门,上班平常使用一天的时间绝对没有问题,用点心省电这个软件,充满电的情况下,使用时间为23小时06分,当然晚上还是要充电的。3.SONY自带的界面UI很美观,而且自带多种主题选择,整个系统的使用非常顺畅,UI的设计很不错,也是我入手购买的很大一原因.4.配置较主流,内置16G的存储容量,可使用的也有12G左右,无法扩展,但是也够用,省去再买内存卡的花费。二、缺点:1.手机的工艺细节上有少许的不满意的地方,例如很多人提过的,塑料天线盖子与后盖的铝合金拼合处有点点缝隙,另外有人提到过透明带可能会起泡,当然我的机子目前还没有。还有一点就是充电插口和HVI的高清接口是没有盖子,这就有进灰尘的一个烦恼,毕竟充电是天天要用的,需要保养好点。2.画面颜色有点点偏色,饱和度很高,绿色会绿一些,是因为有SONY自带优化的原因。3.电池无法更换,如果出差什么的,要自配一个扩展移动电源。4.IU界面虽然很美观,但是毕竟SONY的三键操作会与其它安卓有点点不同,返回键在最左边,所以需要适应。以上是本人的一点点观点,只代表个人看法,希望对大家有所帮助,当然也许各个地区的版本会有所差异,恳请各位指正,谢谢!!!', 'label': 1}
{'text': 'os#operation_performance', 'text_pair': '入手港版白色苹果IPhone5使用2周,谈谈使用感受~使用到现在已经2周了,先谈谈感受1.机子再怎么用心保护也会受损,特别是边框斜边抛光部分,已经损了牙签大小,不知道怎么弄的,所以担心受损或者完美主义记得买回来就带套2.机子虽然容易受损,但比4S坚强很多,朋友同时买得机子,开了LED提醒,来电吓到家人当场甩出去,后边框角5*2mm面积撞平了,其他完好无损,提醒大家谨慎开LED提醒3.背后的苹果LOGO还有IPHONE字样也是抛光的,我的机子没事,朋友的已经花了,怎么擦都擦不了4.屏幕正常使用,没贴膜,放口袋放包里,目测无刮痕5.充电时间没去算,充满可以用10多个小时,正常wifi+gprs上网打电话6.机子很轻,看了半个月5再去看4S,真的不适应,感觉4S很重屏幕很窄感觉4S很重屏幕很窄7.Siri的粤语跟普通话辨认都不错,就是没广告上的反应那么快8.勿扰模式很不错,休眠情况可以拒绝对方二次来电?试了电话打不进来9.外观上,因为本人不喜欢黑色版的,故选择了白色的,感觉很有高雅贵族气息(非装逼,只是这么觉得)边框的损耗问题,也不是说非常容易擦花,但是我是裸奔的,也是轻拿轻放,但还是背面左下角有了个非常不明显的伤痕(个人感觉边框有点锋利,因此有些许碰撞的话有可能导致刮花,下面图片会指出)10.硬件上,使用起来确实是比4s要快,非常的流畅!屏幕的色彩显示要比4s好上很多,非常好看摄像头就没感觉有提升多少,不过还是非常优秀的不得不说一下配的那个什么pod的新款耳机,真的有点失望了,可能太期待它的音质效果了,戴上去也算不上很舒适,反而觉得很迷你,音质感觉还是没有什么提升啊,甚至还感觉比不上4s那耳机11.系统上,我不知道是自己太容易满足还是大家要求太高,我觉得ios6真的是很不错不得不说的是电量!真的是优化得很好,我连续用了3、4个小时,有玩游戏,上网,下载东西,听歌等等,还剩百分之五十多换作以前的4s这个使用量顶多就只剩百分之三十了一般使用一天一充或者一天半一充是完全没有问题的还有passbook,非常的方便和实惠,这个要大家体验了,其他的话地图没什么感觉,不是太好,也不是大家喷的那么差,反正中国内使用我觉得可以了,但是不要卫星模式就好了', 'label': 1}
-----dev sample data-----
{'text': 'software#design_features', 'text_pair': '三星 GALAXY Note II入手过程及三天的感受。。。入手N7100原因:1、由于本人主机一直是IP4联通的合约机,使用快2年了,越来越受不了IP4的听筒音量,相对于我LP的4S那叫一个小啊,在室外嘈杂的地方基本要按在耳朵上听,带着耳机又麻烦。所以想换掉IP4;2、严重的审美疲劳,不说大街上到处都是IP了,自己看着自己的IP也都心烦了;3、系统不断升级,IP4越来越力不从心了,比起4S真的感觉慢了好多,尤其是越狱之后,各种插件导致使用速度缓慢,最后只安装了百度输入法和KuaiDial等基本使用软件,连美化都不做了;4、严重感觉系统封闭对于使用的不便利,尤其是我经常会使用各种文档,导入手机很麻烦,也许是我没有那么好的耐心了;5、对IP5和IOS6比较严重的失望,没有太大的亮点来吸引我。综上几点,本人真心想换个手机,当初想用I9220,周围几个朋友和同事都入手了,但是总是觉得系统和UI不是很好,但是总是觉得系统和UI不是很好,并且自己不喜欢note不标准的分辨率,所以一直没有入手。后来看到S3,真心觉得眼前一亮,可是1G的RAM又感觉不给力,韩版总是会存在问题,所以一直在犹豫中……直到NOTEⅡ的发布。1、在系统的操作上没有感觉比IP差,滑动的流畅性上面几乎看不出来,觉得还是CPU和内存给力,觉得还是CPU和内存给力,当然4.11的也占了很大的原因,游戏么,就不想太多了,跟IOS的自然没法比;2、屏幕确实有点灰蒙蒙的感觉,不像I9100那样艳丽,论坛里的高手有说这个是程序的问题,不知道是不是以后会升级解决;3、使用的便利性上要远远超过IP,虽然这个大家都知道,而且我也用过小米等手机,但是此时真的感觉方便啊;4、昨天手机提示升级,通过WIFI直接完成升级,本以为是解决灰蒙蒙和增加多任务窗口的,结果不是,有点失望;5、电池很给力,早上一个小时的3G上网,掉了7个点的电量,比我换过电池的IP4不知道强了多少啊;6、信号不错,在我位置上打电话很好,不会掉线,而IP4因为众所周知的原因,不能在我的位置上打电话;7、跟同事的S3屏幕比较,感觉没有S3的艳丽和清晰,不知道是不是我的眼睛有问题;8、自己回家把作为副机的IP4拿出来,突然吓了一跳,怎么这么小啊,真的,没有夸张。9、不想ROOT了,尤其现在都是线刷,只想卡刷,并且本身2G的RAM,真的不影响使用,只是开机自动运行那么多软件,心里会有点不舒服。总之,这是个没有让我失望的手机,无论信号,语音、屏幕,还是一直不让我喜欢的安卓的流畅性都能满足我的需求。应该说,你买了它不会后悔,但是你要想好了,有可能你不会适应小屏幕的手机了。', 'label': 0}
{'text': 'display#design_features', 'text_pair': '三星 GALAXY Note II入手过程及三天的感受。。。入手N7100原因:1、由于本人主机一直是IP4联通的合约机,使用快2年了,越来越受不了IP4的听筒音量,相对于我LP的4S那叫一个小啊,在室外嘈杂的地方基本要按在耳朵上听,带着耳机又麻烦。所以想换掉IP4;2、严重的审美疲劳,不说大街上到处都是IP了,自己看着自己的IP也都心烦了;3、系统不断升级,IP4越来越力不从心了,比起4S真的感觉慢了好多,尤其是越狱之后,各种插件导致使用速度缓慢,最后只安装了百度输入法和KuaiDial等基本使用软件,连美化都不做了;4、严重感觉系统封闭对于使用的不便利,尤其是我经常会使用各种文档,导入手机很麻烦,也许是我没有那么好的耐心了;5、对IP5和IOS6比较严重的失望,没有太大的亮点来吸引我。综上几点,本人真心想换个手机,当初想用I9220,周围几个朋友和同事都入手了,但是总是觉得系统和UI不是很好,但是总是觉得系统和UI不是很好,并且自己不喜欢note不标准的分辨率,所以一直没有入手。后来看到S3,真心觉得眼前一亮,可是1G的RAM又感觉不给力,韩版总是会存在问题,所以一直在犹豫中……直到NOTEⅡ的发布。1、在系统的操作上没有感觉比IP差,滑动的流畅性上面几乎看不出来,觉得还是CPU和内存给力,觉得还是CPU和内存给力,当然4.11的也占了很大的原因,游戏么,就不想太多了,跟IOS的自然没法比;2、屏幕确实有点灰蒙蒙的感觉,不像I9100那样艳丽,论坛里的高手有说这个是程序的问题,不知道是不是以后会升级解决;3、使用的便利性上要远远超过IP,虽然这个大家都知道,而且我也用过小米等手机,但是此时真的感觉方便啊;4、昨天手机提示升级,通过WIFI直接完成升级,本以为是解决灰蒙蒙和增加多任务窗口的,结果不是,有点失望;5、电池很给力,早上一个小时的3G上网,掉了7个点的电量,比我换过电池的IP4不知道强了多少啊;6、信号不错,在我位置上打电话很好,不会掉线,而IP4因为众所周知的原因,不能在我的位置上打电话;7、跟同事的S3屏幕比较,感觉没有S3的艳丽和清晰,不知道是不是我的眼睛有问题;8、自己回家把作为副机的IP4拿出来,突然吓了一跳,怎么这么小啊,真的,没有夸张。9、不想ROOT了,尤其现在都是线刷,只想卡刷,并且本身2G的RAM,真的不影响使用,只是开机自动运行那么多软件,心里会有点不舒服。总之,这是个没有让我失望的手机,无论信号,语音、屏幕,还是一直不让我喜欢的安卓的流畅性都能满足我的需求。应该说,你买了它不会后悔,但是你要想好了,有可能你不会适应小屏幕的手机了。', 'label': 0}
{'text': 'phone#quality', 'text_pair': '新入手三天华为S8600使用感受淘宝购买 1670包邮,拿到手之后,第一感觉很不错,说说优缺点!优点:1.做工很不错,大厂品质,不比那些外资差;2.手机份量很足,手感好,外观很漂亮;3.通话质量好,信号不错,声音也不轻;4.机器配置可以,正常运行速度比之前买的山寨机好多了(山寨机都是假的);5.当地有售后服务点,比较方便;6.电池虽然不能换,但像一天几十个电话,还是能用一天的,比较给力;缺点:1.电信定制的软件太多,占用了很多内存,不过现在ROOT之后把不要的软件全删了,感觉运行速度比刚拿来时更快了;2.电池不能更换,如果长时间用手机的人要准备好移动充电器;3.配置跑大型游戏还是不行,会卡;4.机器新,配件少(保护套等);5.WIFI信号没有我老婆的HTC G11强;6.震动的幅度太小,开车放口袋感觉不到;7.单通,一个号码通话中,另一个号码打不进来;目前就只有这些,希望大家多交流!!!', 'label': 1}
-----test sample data-----
{'text': 'software#usability', 'text_pair': '刚刚入手8600,体会。刚刚从淘宝购买,1635元(包邮)。1、全新,应该是欧版机,配件也是正品全新。2、在三星官网下载了KIES,可用免费软件非常多,绝对够用。3、不到2000元能买到此种手机,知足了。'}
{'text': 'display#quality', 'text_pair': 'mk16i用后的体验感觉不错,就是有点厚,屏幕分辨率高,运行流畅,就是不知道能不能刷4.0的系统啊'}
{'text': 'phone#operation_performance', 'text_pair': 'mk16i用后的体验感觉不错,就是有点厚,屏幕分辨率高,运行流畅,就是不知道能不能刷4.0的系统啊'}
SKEP模型加载
PaddleNLP已经实现了SKEP预训练模型,可以通过一行代码实现SKEP加载。
句子级情感分析模型是SKEP fine-tune 文本分类常用模型SkepForSequenceClassification。其首先通过SKEP提取句子语义特征,之后将语义特征进行分类。
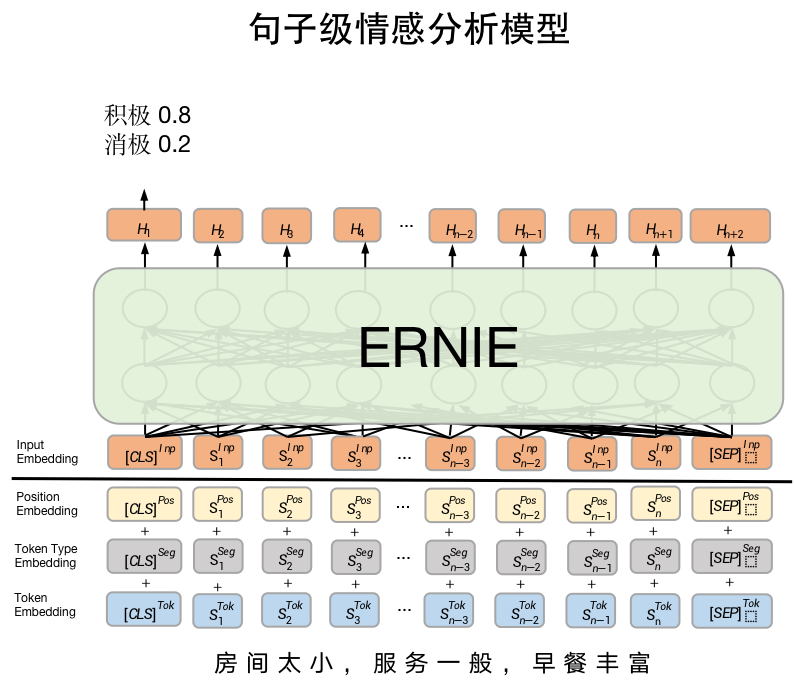
from paddlenlp.transformers import SkepForSequenceClassification, SkepTokenizer
MODEL_NAME = "skep_ernie_1.0_large_ch"
# 指定模型名称,一键加载模型
model = SkepForSequenceClassification.from_pretrained(pretrained_model_name_or_path = MODEL_NAME, num_classes=len(train_ds.label_list))
# 同样地,通过指定模型名称一键加载对应的Tokenizer,用于处理文本数据,如切分token,转token_id等。
tokenizer = SkepTokenizer.from_pretrained(pretrained_model_name_or_path = MODEL_NAME)
[2021-06-21 16:30:20,966] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/skep_ernie_1.0_large_ch/skep_ernie_1.0_large_ch.pdparams
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py:1297: UserWarning: Skip loading for classifier.weight. classifier.weight is not found in the provided dict.
warnings.warn(("Skip loading for {}. ".format(key) + str(err)))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py:1297: UserWarning: Skip loading for classifier.bias. classifier.bias is not found in the provided dict.
warnings.warn(("Skip loading for {}. ".format(key) + str(err)))
[2021-06-21 16:30:31,193] [ INFO] - Found /home/aistudio/.paddlenlp/models/skep_ernie_1.0_large_ch/skep_ernie_1.0_large_ch.vocab.txt
SkepForSequenceClassification可用于句子级情感分析和目标级情感分析任务。其通过预训练模型SKEP获取输入文本的表示,之后将文本表示进行分类。
pretrained_model_name_or_path:模型名称。支持”skep_ernie_1.0_large_ch”,”skep_ernie_2.0_large_en”。- “skep_ernie_1.0_large_ch”:是SKEP模型在预训练ernie_1.0_large_ch基础之上在海量中文数据上继续预训练得到的中文预训练模型;
- “skep_ernie_2.0_large_en”:是SKEP模型在预训练ernie_2.0_large_en基础之上在海量英文数据上继续预训练得到的英文预训练模型;
num_classes: 数据集分类类别数。
关于SKEP模型实现详细信息参考:https://github.com/PaddlePaddle/PaddleNLP/tree/develop/paddlenlp/transformers/skep
数据处理
同样地,我们需要将原始ChnSentiCorp数据处理成模型可以读入的数据格式。
SKEP模型对中文文本处理按照字粒度进行处理,我们可以使用PaddleNLP内置的SkepTokenizer完成一键式处理。
import os
from functools import partial
import numpy as np
import paddle
import paddle.nn.functional as F
from paddlenlp.data import Stack, Tuple, Pad
from utils import create_dataloader
def convert_example(example,
tokenizer,
max_seq_length=512,
is_test=False):
"""
Builds model inputs from a sequence or a pair of sequence for sequence classification tasks
by concatenating and adding special tokens. And creates a mask from the two sequences passed
to be used in a sequence-pair classification task.
A skep_ernie_1.0_large_ch/skep_ernie_2.0_large_en sequence has the following format:
::
- single sequence: ``[CLS] X [SEP]``
- pair of sequences: ``[CLS] A [SEP] B [SEP]``
A skep_ernie_1.0_large_ch/skep_ernie_2.0_large_en sequence pair mask has the following format:
::
0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1
| first sequence | second sequence |
If `token_ids_1` is `None`, this method only returns the first portion of the mask (0s).
Args:
example(obj:`list[str]`): List of input data, containing text and label if it have label.
tokenizer(obj:`PretrainedTokenizer`): This tokenizer inherits from :class:`~paddlenlp.transformers.PretrainedTokenizer`
which contains most of the methods. Users should refer to the superclass for more information regarding methods.
max_seq_len(obj:`int`): The maximum total input sequence length after tokenization.
Sequences longer than this will be truncated, sequences shorter will be padded.
is_test(obj:`False`, defaults to `False`): Whether the example contains label or not.
Returns:
input_ids(obj:`list[int]`): The list of token ids.
token_type_ids(obj: `list[int]`): List of sequence pair mask.
label(obj:`int`, optional): The input label if not is_test.
"""
# 将原数据处理成model可读入的格式,enocded_inputs是一个dict,包含input_ids、token_type_ids等字段
encoded_inputs = tokenizer(
text=example["text"], max_seq_len=max_seq_length)
# input_ids:对文本切分token后,在词汇表中对应的token id
input_ids = encoded_inputs["input_ids"]
# token_type_ids:当前token属于句子1还是句子2,即上述图中表达的segment ids
token_type_ids = encoded_inputs["token_type_ids"]
if not is_test:
# label:情感极性类别
label = np.array([example["label"]], dtype="int64")
return input_ids, token_type_ids, label
else:
# qid:每条数据的编号
qid = np.array([example["qid"]], dtype="int64")
return input_ids, token_type_ids, qid
# 批量数据大小
batch_size = 32
# 文本序列最大长度
max_seq_length = 256
# 将数据处理成模型可读入的数据格式
trans_func = partial(
convert_example,
tokenizer=tokenizer,
max_seq_length=max_seq_length)
# 将数据组成批量式数据,如
# 将不同长度的文本序列padding到批量式数据中最大长度
# 将每条数据label堆叠在一起
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # input_ids
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # token_type_ids
Stack() # labels
): [data for data in fn(samples)]
train_data_loader = create_dataloader(
train_ds,
mode='train',
batch_size=batch_size,
batchify_fn=batchify_fn,
trans_fn=trans_func)
dev_data_loader = create_dataloader(
dev_ds,
mode='dev',
batch_size=batch_size,
batchify_fn=batchify_fn,
trans_fn=trans_func)
模型训练和评估
定义损失函数、优化器以及评价指标后,即可开始训练。
推荐超参设置:
max_seq_length=256batch_size=48learning_rate=2e-5epochs=10
实际运行时可以根据显存大小调整batch_size和max_seq_length大小。
import time
from utils import evaluate
# 训练轮次
epochs = 10
# 训练过程中保存模型参数的文件夹
# ckpt_dir = "skep_ckpt"
# len(train_data_loader)一轮训练所需要的step数
num_training_steps = len(train_data_loader) * epochs
# Generate parameter names needed to perform weight decay.
# All bias and LayerNorm parameters are excluded.
decay_params = [
p.name for n, p in model.named_parameters()
if not any(nd in n for nd in ["bias", "norm"])
]
# Adam优化器
optimizer = paddle.optimizer.AdamW(
learning_rate=2e-5,
parameters=model.parameters(),
weight_decay=0.01,
apply_decay_param_fun=lambda x: x in decay_params)
# 交叉熵损失函数
criterion = paddle.nn.loss.CrossEntropyLoss()
# accuracy评价指标
metric = paddle.metric.Accuracy()
# 开启训练
global_step = 0
global_accu = 0.0
tic_train = time.time()
for epoch in range(1, epochs + 1):
for step, batch in enumerate(train_data_loader, start=1):
input_ids, token_type_ids, labels = batch
# 喂数据给model
logits = model(input_ids, token_type_ids)
# 计算损失函数值
loss = criterion(logits, labels)
# 预测分类概率值
probs = F.softmax(logits, axis=1)
# 计算acc
correct = metric.compute(probs, labels)
metric.update(correct)
acc = metric.accumulate()
global_step += 1
if global_step % 20 == 0:
print(
"global step %d, epoch: %d, batch: %d, loss: %.5f, accu: %.5f, speed: %.2f step/s"
% (global_step, epoch, step, loss, acc,
10 / (time.time() - tic_train)))
tic_train = time.time()
# 反向梯度回传,更新参数
loss.backward()
optimizer.step()
optimizer.clear_grad()
if global_step % 100 == 0:
# 评估当前训练的模型
eva_accu = evaluate(model, criterion, metric, dev_data_loader)
if eva_accu > global_accu:
print(f'evaluate accu: {eva_accu}>history accu:{global_accu} ==> save the model!')
global_accu = eva_accu
save_dir = os.path.join(f'checkpoint_{traindataset}_{MODEL_NAME}', "model_%d_%.3f" % (global_step,global_accu))
if not os.path.exists(save_dir):
os.makedirs(save_dir)
save_param_path = os.path.join(save_dir, 'model_state.pdparams')
paddle.save(model.state_dict(), save_param_path)
# 保存当前模型参数等
save_dir = os.path.join(f'checkpoint_{traindataset}_{MODEL_NAME}', "model_%d_last" % (global_step))
if not os.path.exists(save_dir):
os.makedirs(save_dir)
# 保存tokenizer的词表等
save_param_path = os.path.join(save_dir, 'model_state.pdparams')
paddle.save(model.state_dict(), save_param_path)
预测提交结果
使用训练得到的模型还可以对文本进行情感预测。
import numpy as np
import paddle
# 处理测试集数据
trans_func = partial(
convert_example,
tokenizer=tokenizer,
max_seq_length=max_seq_length,
is_test=True)
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # input
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # segment
Stack() # qid
): [data for data in fn(samples)]
test_data_loader = create_dataloader(
test_ds,
mode='test',
batch_size=12,
batchify_fn=batchify_fn,
trans_fn=trans_func)
# for i in test_data_loader:
# print(i)
# 根据实际运行情况,更换加载的参数路径
params_path = os.path.join(f'checkpoint_{traindataset}_{MODEL_NAME}', 'model_300_best','model_state.pdparams')
if params_path and os.path.isfile(params_path):
# 加载模型参数
state_dict = paddle.load(params_path)
model.set_dict(state_dict)
print("Loaded parameters from %s" % params_path)
else:
print("Can not load parameters from %s, please check your path!" % params_path)
Loaded parameters from checkpoint_SE-ABSA16_CAME_skep_ernie_1.0_large_ch/model_300_best/model_state.pdparams
label_map = {0: '0', 1: '1'}
results = []
# 切换model模型为评估模式,关闭dropout等随机因素
model.eval()
for batch in test_data_loader:
try:
input_ids, token_type_ids, qids = batch
except Exception as e:
print(batch)
raise e
# print(input_ids,token_type_ids,qids)
# break
# 喂数据给模型
logits = model(input_ids, token_type_ids)
# 预测分类
probs = F.softmax(logits, axis=-1)
idx = paddle.argmax(probs, axis=1).numpy()
idx = idx.tolist()
labels = [label_map[i] for i in idx]
qids = qids.numpy().tolist()
results.extend(zip(qids, labels))
res_dir = "./results"
if not os.path.exists(res_dir):
os.makedirs(res_dir)
# 写入预测结果
with open(os.path.join(res_dir, f"{traindataset}.tsv"), 'w', encoding="utf8") as f:
f.write("index\tprediction\n")
for qid, label in results:
f.write(str(qid[0])+"\t"+label+"\n")
Part C.2 目标级情感分析
在电商产品分析场景下,除了分析整体商品的情感极性外,还细化到以商品具体的“方面”为分析主体进行情感分析(aspect-level),如下、:
- 这个薯片口味有点咸,太辣了,不过口感很脆。
关于薯片的口味方面是一个负向评价(咸,太辣),然而对于口感方面却是一个正向评价(很脆)。
- 我很喜欢夏威夷,就是这边的海鲜太贵了。
关于夏威夷是一个正向评价(喜欢),然而对于夏威夷的海鲜却是一个负向评价(价格太贵)。
</br>

常用数据集
千言数据集已提供了许多任务常用数据集。 其中情感分析数据集下载链接:https://aistudio.baidu.com/aistudio/competition/detail/50/?isFromLUGE=TRUE
SE-ABSA16_PHNS数据集是关于手机的目标级情感分析数据集。PaddleNLP已经内置了该数据集,加载方式,如下:
# from paddlenlp.datasets import load_dataset
# train_ds, test_ds = load_dataset("seabsa16",'phns', splits=["train", "test"])
# print(train_ds[0])
# print(train_ds[1])
# print(train_ds[2])
100%|██████████| 381/381 [00:00<00:00, 32636.17it/s]
{'text': 'phone#design_features', 'text_pair': '今天有幸拿到了港版白色iPhone 5真机,试玩了一下,说说感受吧:1. 真机尺寸宽度与4/4s保持一致没有变化,长度多了大概一厘米,也就是之前所说的多了一排的图标。2. 真机重量比上一代轻了很多,个人感觉跟i9100的重量差不多。(用惯上一代的朋友可能需要一段时间适应了)3. 由于目前还没有版的SIM卡,无法插卡使用,有购买的朋友要注意了,并非简单的剪卡就可以用,而是需要去运营商更换新一代的SIM卡。4. 屏幕显示效果确实比上一代有进步,不论是从清晰度还是不同角度的视角,iPhone 5绝对要更上一层,我想这也许是相对上一代最有意义的升级了。5. 新的数据接口更小,比上一代更好用更方便,使用的过程会有这样的体会。6. 从简单的几个操作来讲速度比4s要快,这个不用测试软件也能感受出来,比如程序的调用以及照片的拍摄和浏览。不过,目前水货市场上坑爹的价格,最好大家可以再观望一下,不要急着出手。', 'label': 1}
{'text': 'display#quality', 'text_pair': '今天有幸拿到了港版白色iPhone 5真机,试玩了一下,说说感受吧:1. 真机尺寸宽度与4/4s保持一致没有变化,长度多了大概一厘米,也就是之前所说的多了一排的图标。2. 真机重量比上一代轻了很多,个人感觉跟i9100的重量差不多。(用惯上一代的朋友可能需要一段时间适应了)3. 由于目前还没有版的SIM卡,无法插卡使用,有购买的朋友要注意了,并非简单的剪卡就可以用,而是需要去运营商更换新一代的SIM卡。4. 屏幕显示效果确实比上一代有进步,不论是从清晰度还是不同角度的视角,iPhone 5绝对要更上一层,我想这也许是相对上一代最有意义的升级了。5. 新的数据接口更小,比上一代更好用更方便,使用的过程会有这样的体会。6. 从简单的几个操作来讲速度比4s要快,这个不用测试软件也能感受出来,比如程序的调用以及照片的拍摄和浏览。不过,目前水货市场上坑爹的价格,最好大家可以再观望一下,不要急着出手。', 'label': 1}
{'text': 'ports#connectivity', 'text_pair': '今天有幸拿到了港版白色iPhone 5真机,试玩了一下,说说感受吧:1. 真机尺寸宽度与4/4s保持一致没有变化,长度多了大概一厘米,也就是之前所说的多了一排的图标。2. 真机重量比上一代轻了很多,个人感觉跟i9100的重量差不多。(用惯上一代的朋友可能需要一段时间适应了)3. 由于目前还没有版的SIM卡,无法插卡使用,有购买的朋友要注意了,并非简单的剪卡就可以用,而是需要去运营商更换新一代的SIM卡。4. 屏幕显示效果确实比上一代有进步,不论是从清晰度还是不同角度的视角,iPhone 5绝对要更上一层,我想这也许是相对上一代最有意义的升级了。5. 新的数据接口更小,比上一代更好用更方便,使用的过程会有这样的体会。6. 从简单的几个操作来讲速度比4s要快,这个不用测试软件也能感受出来,比如程序的调用以及照片的拍摄和浏览。不过,目前水货市场上坑爹的价格,最好大家可以再观望一下,不要急着出手。', 'label': 1}
SKEP模型加载
目标级情感分析模型同样使用SkepForSequenceClassification模型,但目标级情感分析模型的输入不单单是一个句子,而是句对。一个句子描述“评价对象方面(aspect)”,另一个句子描述”对该方面的评论”。如下图所示。
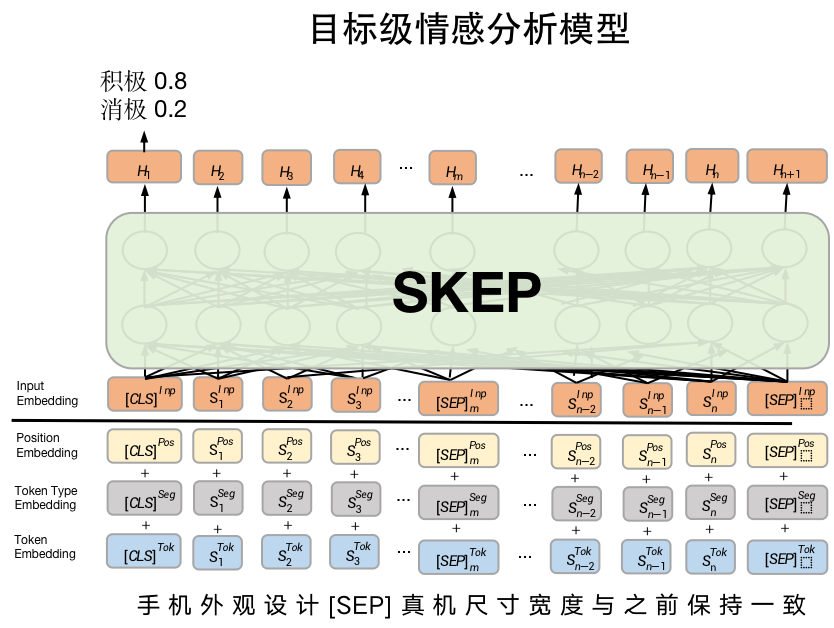
from paddlenlp.transformers import SkepForSequenceClassification, SkepTokenizer
MODEL_NAME = "skep_ernie_1.0_large_ch"
# 指定模型名称,一键加载模型
model = SkepForSequenceClassification.from_pretrained(pretrained_model_name_or_path = MODEL_NAME, num_classes=len(train_ds.label_list))
# 同样地,通过指定模型名称一键加载对应的Tokenizer,用于处理文本数据,如切分token,转token_id等。
tokenizer = SkepTokenizer.from_pretrained(pretrained_model_name_or_path = MODEL_NAME)
[2021-06-21 17:15:18,011] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/skep_ernie_1.0_large_ch/skep_ernie_1.0_large_ch.pdparams
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py:1297: UserWarning: Skip loading for classifier.weight. classifier.weight is not found in the provided dict.
warnings.warn(("Skip loading for {}. ".format(key) + str(err)))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py:1297: UserWarning: Skip loading for classifier.bias. classifier.bias is not found in the provided dict.
warnings.warn(("Skip loading for {}. ".format(key) + str(err)))
[2021-06-21 17:15:28,310] [ INFO] - Found /home/aistudio/.paddlenlp/models/skep_ernie_1.0_large_ch/skep_ernie_1.0_large_ch.vocab.txt
数据处理
同样地,我们需要将原始SE_ABSA16_PHNS数据处理成模型可以读入的数据格式。
SKEP模型对中文文本处理按照字粒度进行处理,我们可以使用PaddleNLP内置的SkepTokenizer完成一键式处理。
from functools import partial
import os
import time
import numpy as np
import paddle
import paddle.nn.functional as F
from paddlenlp.data import Stack, Tuple, Pad
def convert_example(example,
tokenizer,
max_seq_length=512,
is_test=False,
dataset_name="chnsenticorp"):
"""
Builds model inputs from a sequence or a pair of sequence for sequence classification tasks
by concatenating and adding special tokens. And creates a mask from the two sequences passed
to be used in a sequence-pair classification task.
A skep_ernie_1.0_large_ch/skep_ernie_2.0_large_en sequence has the following format:
::
- single sequence: ``[CLS] X [SEP]``
- pair of sequences: ``[CLS] A [SEP] B [SEP]``
A skep_ernie_1.0_large_ch/skep_ernie_2.0_large_en sequence pair mask has the following format:
::
0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1
| first sequence | second sequence |
If `token_ids_1` is `None`, this method only returns the first portion of the mask (0s).
note: There is no need token type ids for skep_roberta_large_ch model.
Args:
example(obj:`list[str]`): List of input data, containing text and label if it have label.
tokenizer(obj:`PretrainedTokenizer`): This tokenizer inherits from :class:`~paddlenlp.transformers.PretrainedTokenizer`
which contains most of the methods. Users should refer to the superclass for more information regarding methods.
max_seq_len(obj:`int`): The maximum total input sequence length after tokenization.
Sequences longer than this will be truncated, sequences shorter will be padded.
is_test(obj:`False`, defaults to `False`): Whether the example contains label or not.
dataset_name((obj:`str`, defaults to "chnsenticorp"): The dataset name, "chnsenticorp" or "sst-2".
Returns:
input_ids(obj:`list[int]`): The list of token ids.
token_type_ids(obj: `list[int]`): List of sequence pair mask.
label(obj:`numpy.array`, data type of int64, optional): The input label if not is_test.
"""
encoded_inputs = tokenizer(
text=example["text"],
text_pair=example["text_pair"],
max_seq_len=max_seq_length)
input_ids = encoded_inputs["input_ids"]
token_type_ids = encoded_inputs["token_type_ids"]
if not is_test:
label = np.array([example["label"]], dtype="int64")
return input_ids, token_type_ids, label
else:
return input_ids, token_type_ids
from utils import create_dataloader
# 处理的最大文本序列长度
max_seq_length=256
# 批量数据大小
batch_size=32
# 将数据处理成model可读入的数据格式
trans_func = partial(
convert_example,
tokenizer=tokenizer,
max_seq_length=max_seq_length)
# 将数据组成批量式数据,如
# 将不同长度的文本序列padding到批量式数据中最大长度
# 将每条数据label堆叠在一起
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # input_ids
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # token_type_ids
Stack(dtype="int64") # labels
): [data for data in fn(samples)]
train_data_loader = create_dataloader(
train_ds,
mode='train',
batch_size=batch_size,
batchify_fn=batchify_fn,
trans_fn=trans_func)
dev_data_loader = create_dataloader(
dev_ds,
mode='dev',
batch_size=batch_size,
batchify_fn=batchify_fn,
trans_fn=trans_func)
模型训练
定义损失函数、优化器以及评价指标后,即可开始训练。
import time
from utils import evaluate
# 训练轮次
epochs = 20
# 总共需要训练的step数
num_training_steps = len(train_data_loader) * epochs
# Generate parameter names needed to perform weight decay.
# All bias and LayerNorm parameters are excluded.
decay_params = [
p.name for n, p in model.named_parameters()
if not any(nd in n for nd in ["bias", "norm"])
]
# Adam优化器
optimizer = paddle.optimizer.AdamW(
learning_rate=2e-5,
parameters=model.parameters(),
weight_decay=0.01,
apply_decay_param_fun=lambda x: x in decay_params)
# 交叉熵损失
criterion = paddle.nn.loss.CrossEntropyLoss()
# Accuracy评价指标
metric = paddle.metric.Accuracy()
# 开启训练
global_step = 0
global_accu = 0.0
tic_train = time.time()
for epoch in range(1, epochs + 1):
for step, batch in enumerate(train_data_loader, start=1):
input_ids, token_type_ids, labels = batch
# 喂数据给model
logits = model(input_ids, token_type_ids)
# 计算损失函数值
loss = criterion(logits, labels)
# 预测分类概率
probs = F.softmax(logits, axis=1)
# 计算acc
correct = metric.compute(probs, labels)
metric.update(correct)
acc = metric.accumulate()
global_step += 1
if global_step % 20 == 0:
print(
"global step %d, epoch: %d, batch: %d, loss: %.5f, acc: %.5f, speed: %.2f step/s"
% (global_step, epoch, step, loss, acc,
10 / (time.time() - tic_train)))
tic_train = time.time()
# 反向梯度回传,更新参数
loss.backward()
optimizer.step()
optimizer.clear_grad()
if global_step % 100 == 0:
# 评估当前训练的模型
eva_accu = evaluate(model, criterion, metric, dev_data_loader)
if eva_accu > global_accu:
print(f'evaluate accu: {eva_accu}>history accu:{global_accu} ==> save the model!')
global_accu = eva_accu
save_dir = os.path.join(f'checkpoint_{traindataset}_{MODEL_NAME}', "model_%d_%.3f" % (global_step,global_accu))
if not os.path.exists(save_dir):
os.makedirs(save_dir)
save_param_path = os.path.join(save_dir, 'model_state.pdparams')
paddle.save(model.state_dict(), save_param_path)
#came使用300保存
# if global_step == 300:
# save_dir = os.path.join(f'checkpoint_{traindataset}_{MODEL_NAME}', "model_%d_best" % (global_step))
# if not os.path.exists(save_dir):
# os.makedirs(save_dir)
# save_param_path = os.path.join(save_dir, 'model_state.pdparams')
# paddle.save(model.state_dict(), save_param_path)
# 保存当前模型参数等
save_dir = os.path.join(f'checkpoint_{traindataset}_{MODEL_NAME}', "model_%d_last" % (global_step))
if not os.path.exists(save_dir):
os.makedirs(save_dir)
# 保存tokenizer的词表等
save_param_path = os.path.join(save_dir, 'model_state.pdparams')
paddle.save(model.state_dict(), save_param_path)
预测提交结果
使用训练得到的模型还可以对评价对象进行情感预测。
@paddle.no_grad()
def predict(model, data_loader, label_map):
"""
Given a prediction dataset, it gives the prediction results.
Args:
model(obj:`paddle.nn.Layer`): A model to classify texts.
data_loader(obj:`paddle.io.DataLoader`): The dataset loader which generates batches.
label_map(obj:`dict`): The label id (key) to label str (value) map.
"""
model.eval()
results = []
for batch in data_loader:
input_ids, token_type_ids = batch
logits = model(input_ids, token_type_ids)
probs = F.softmax(logits, axis=1)
idx = paddle.argmax(probs, axis=1).numpy()
idx = idx.tolist()
labels = [label_map[i] for i in idx]
results.extend(labels)
return results
# 处理测试集数据
label_map = {0: '0', 1: '1'}
trans_func = partial(
convert_example,
tokenizer=tokenizer,
max_seq_length=max_seq_length,
is_test=True)
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # input_ids
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # token_type_ids
): [data for data in fn(samples)]
test_data_loader = create_dataloader(
test_ds,
mode='test',
batch_size=batch_size,
batchify_fn=batchify_fn,
trans_fn=trans_func)
# 根据实际运行情况,更换加载的参数路径
params_path = os.path.join(f'checkpoint_{traindataset}_{MODEL_NAME}', 'model_600_0.678','model_state.pdparams')
if params_path and os.path.isfile(params_path):
# 加载模型参数
state_dict = paddle.load(params_path)
model.set_dict(state_dict)
print("Loaded parameters from %s" % params_path)
else:
print("Can not load parameters from %s, please check your path!" % params_path)
results = predict(model, test_data_loader, label_map)
Loaded parameters from checkpoint_SE-ABSA16_CAME_skep_ernie_1.0_large_ch/model_600_0.678/model_state.pdparams
# 写入预测结果
with open(os.path.join("results", f"{traindataset}.tsv"), 'w', encoding="utf8") as f:
f.write("index\tprediction\n")
for idx, label in enumerate(results):
f.write(str(idx)+"\t"+label+"\n")
print(os.path.join("results", f"{traindataset}.tsv")+' save finished!')
results/SE-ABSA16_CAME.tsv save finished!
将预测文件结果压缩至zip文件,提交千言比赛网站
NOTE: results文件夹中NLPCC14-SC.tsv、SE-ABSA16_CAME.tsv、COTE_BD.tsv、COTE_MFW.tsv、COTE_DP.tsv等文件是为了顺利提交,补齐的文件。 其结果还有待提高。
#将预测文件结果压缩至zip文件,提交
!zip -r results.zip results
以上实现基于PaddleNLP,开源不易,希望大家多多支持~
记得给PaddleNLP点个小小的Star⭐,及时跟踪最新消息和功能哦